EEE339 Digital Engineering
week1
Application Specific Integrated Circuits(ASICS)
ASICs are silicon chips that have been designed for a specific purpose
Full Custom Design
- the highest performance
- the most expensive and time consuming to produce
Semi-Custom Design
for Gate Array:
- predefined on silicon wafer
- need to define the interconnections for final device
for Standard Cell:
- predefined functional blocks improve layout density and performance.
Field Programmable Gate Array (FPGA)
- contain configurable logic resources and memory
- are most useful for prototyping and can be cost effective for low volume production runs.
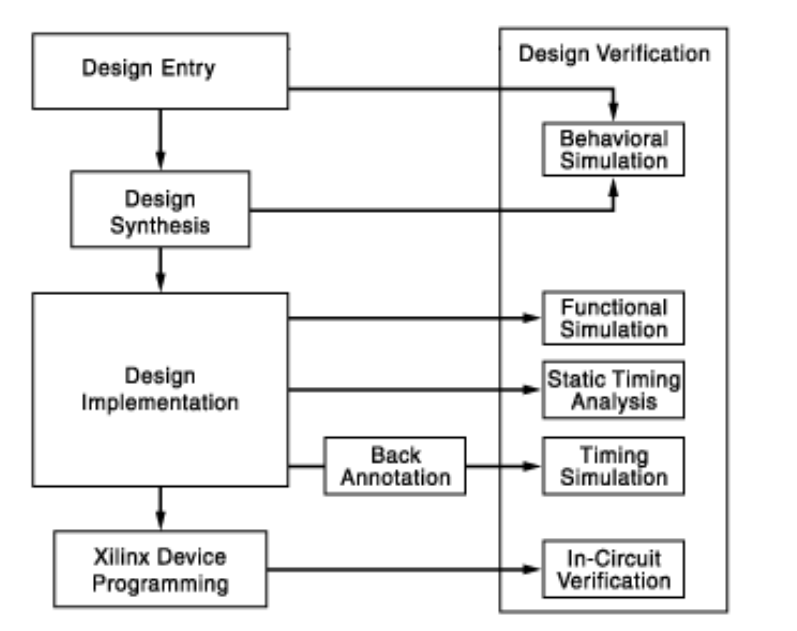
Software tools enable users to enter designs, simulate them to ensure correct functionality and then synthesize a solution for a chosen target device.
Verilog
Basic structure
The module body describes the functionality of the model and the relationship between the input and output ports.
The keyword wire is used to declare internal signals. For example: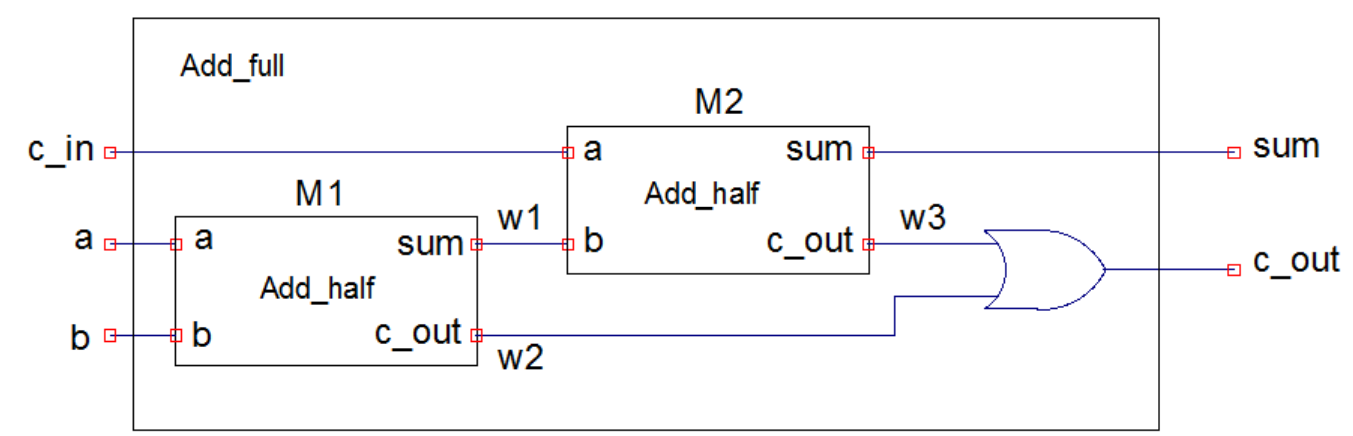
1 | module Add_full(output c_out, sum, input a, b, c_in); |
User Defined Primitives (UDP)
The module descripted by truth table
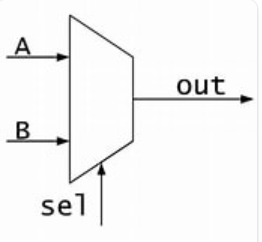
1 | primitive mux_21_udp(output f, input s, a, b); |
Port mapping
Another writing format can not stricly follow the variables’ order.
When the number of ports grows larger, it is easier to associate ports by their names.
1 | Add_half M1 (.b(b), .c_out(w2), .a(a), .sum(w1)); |
Week2
delay module
Propagation delay: time from the input changing to the output responding.
Inertial delay model(for components): changes to the output of ogic gates can not happen instantly due to the charging and discharging of capacitances.(6ps)
If the width of an input pulse is shorter than the inertial delay, the input pulse is supressed and the output will not change in response to it.
Transport delay model(for wire): Time taken for a signal to propagate alonga wire.(1ps)
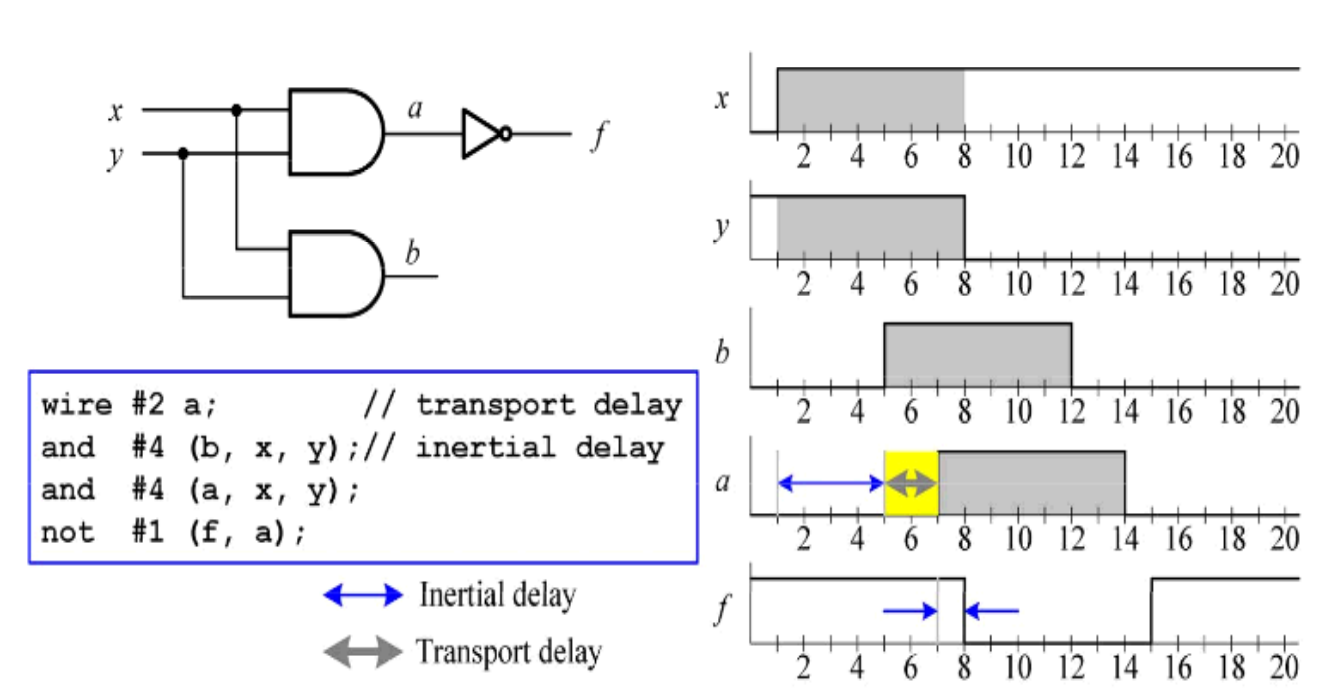
1 | Example: |
#2.58=2.58*10ps=25.8ps rounded to 26ps
four-value logic system
1 – assertion (True)
0 – de-assertion (False)
x – unknown (ambiguous)
z – high impedance (disconnected from driver)
nets: build connections but not store values, like wire.
registers: store value and informations
Week3
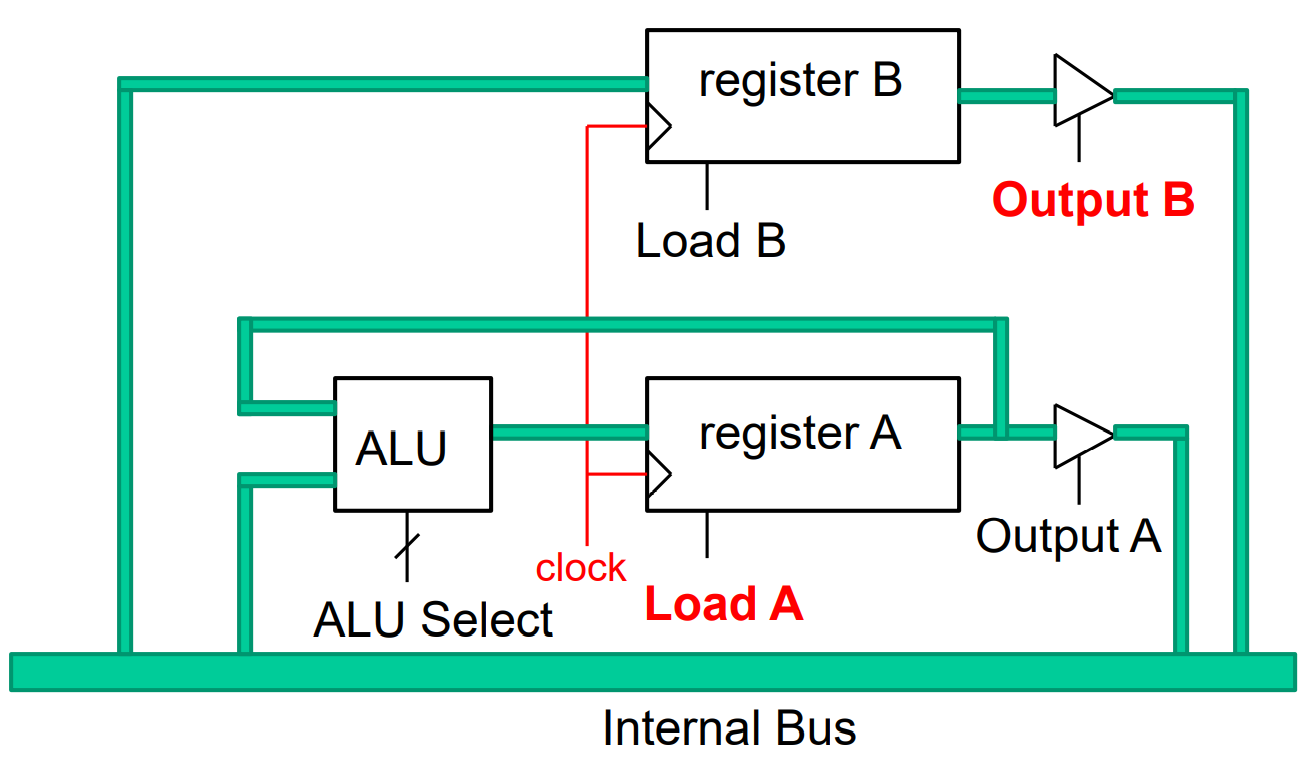
Register file
The registers in a CPU can be grouped into a register file. Two outputs are supplied in order to feed the ALU.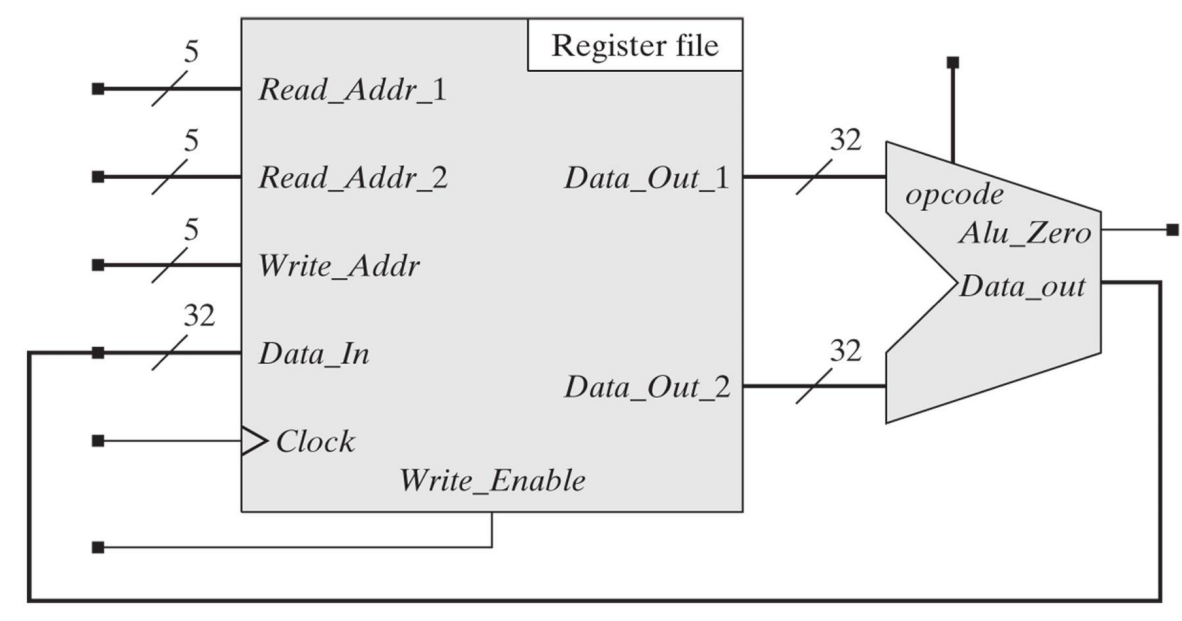
shifter
standard bidirectional shift register: A multiplexer on each input gives a choice of left shift, right shift, parallel load and no-shift, by selecting the source of the D input appropriately.
Combinational Shifter: shift data using multiplexers. B1,2,3 is input and H1,2,3 is output.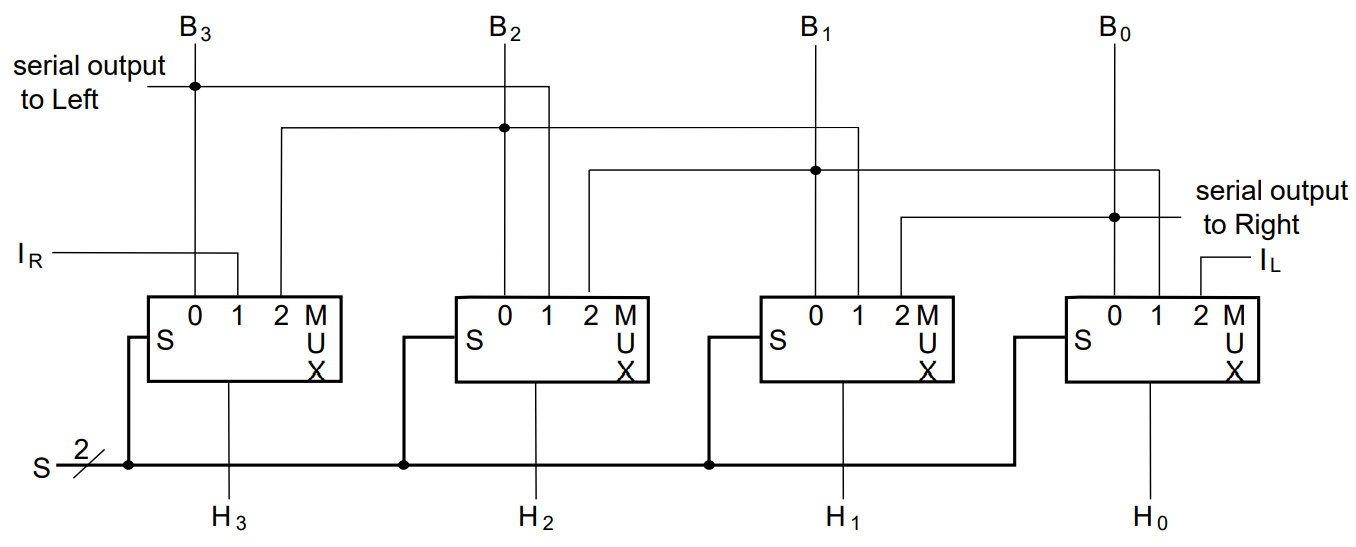
Barrel Shifter: The circuit rotates its contents left from 0 to 3 positions depending on S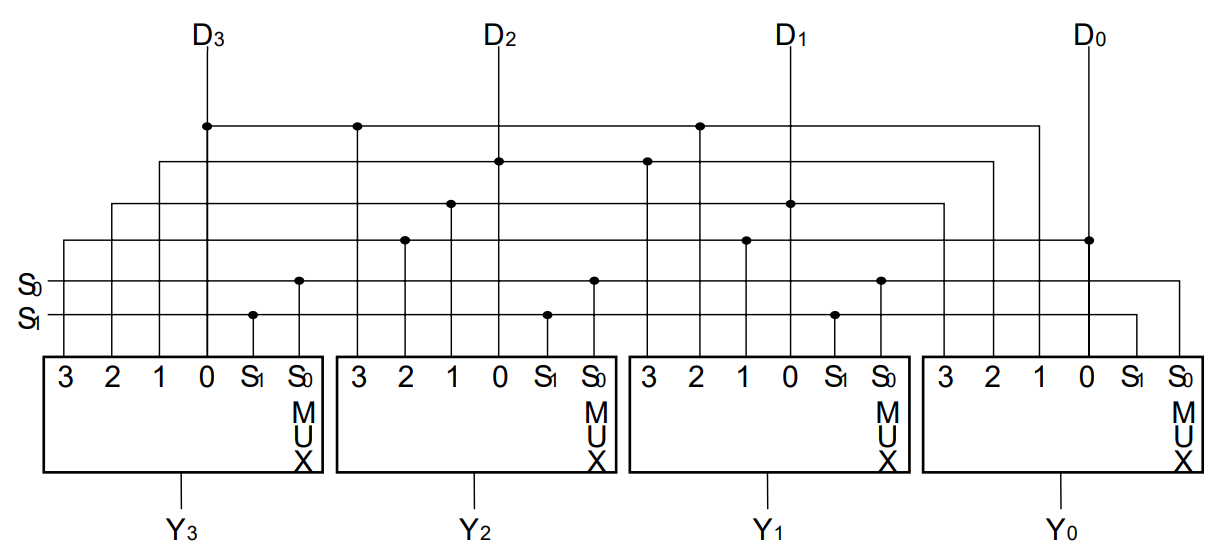
Arithmetic Logic Unit
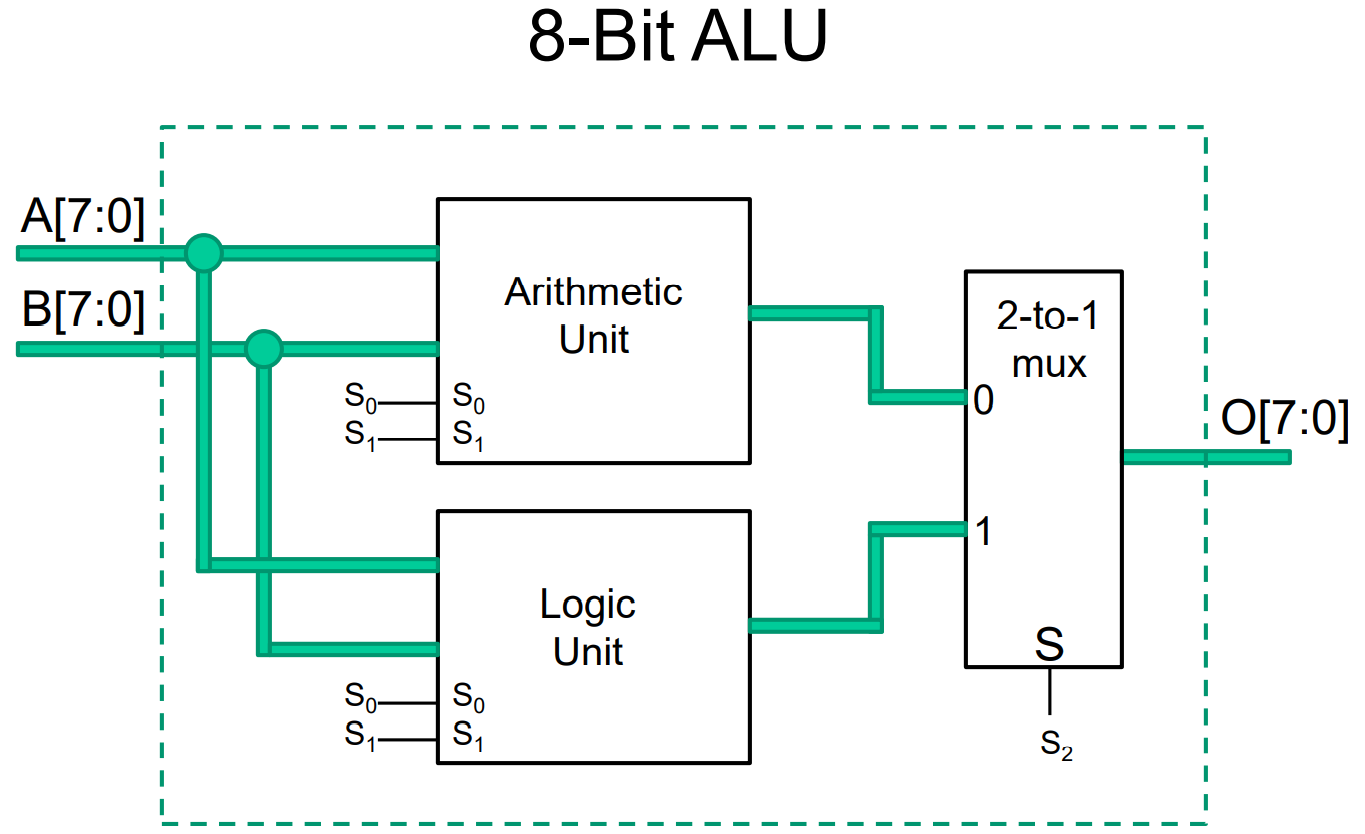
the logic circuit (bitslice):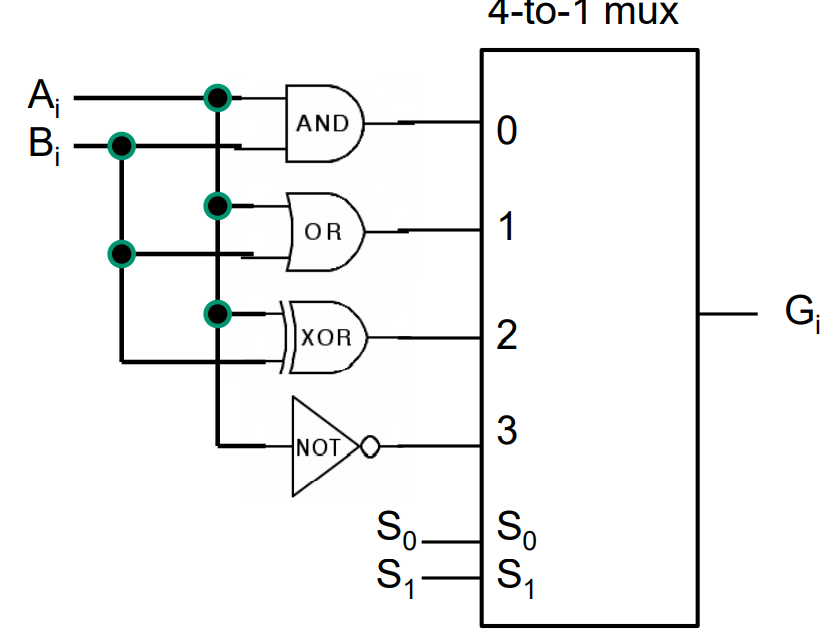
| S1 | S0 | Operation |
|---|---|---|
| 0 | 0 | AND |
| 0 | 1 | OR |
| 1 | 0 | XOR |
| 1 | 1 | NOT |
arithmetic unit: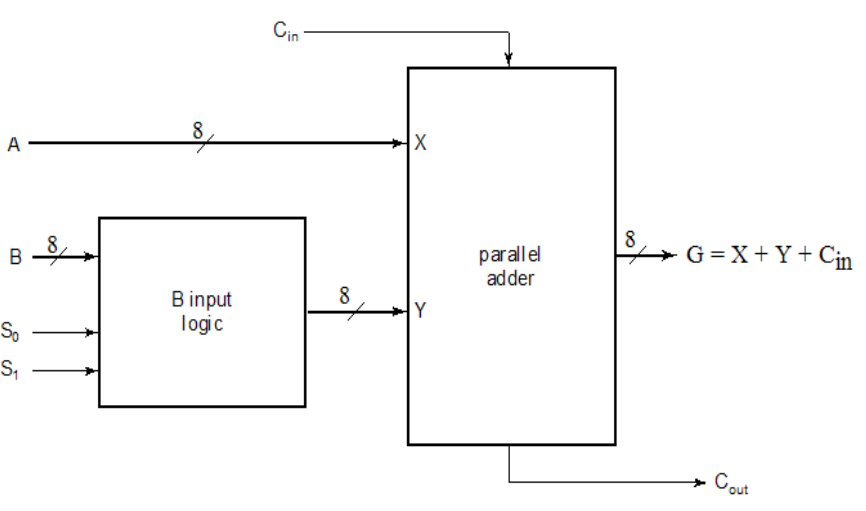
| S1 | S2 | Y | Cin=0 | Cin=1 |
|---|---|---|---|---|
| 0 | 0 | 0 | G=A | G=A+1 |
| 0 | 1 | B | G=A+B | G=A+B+1 |
| 1 | 0 | B’ | G=A+B’ | G=A+B’+1 |
| 1 | 1 | 1 | G=A-1 | G=A |
week4
pictorial representation of 4-bit unsigned inteder: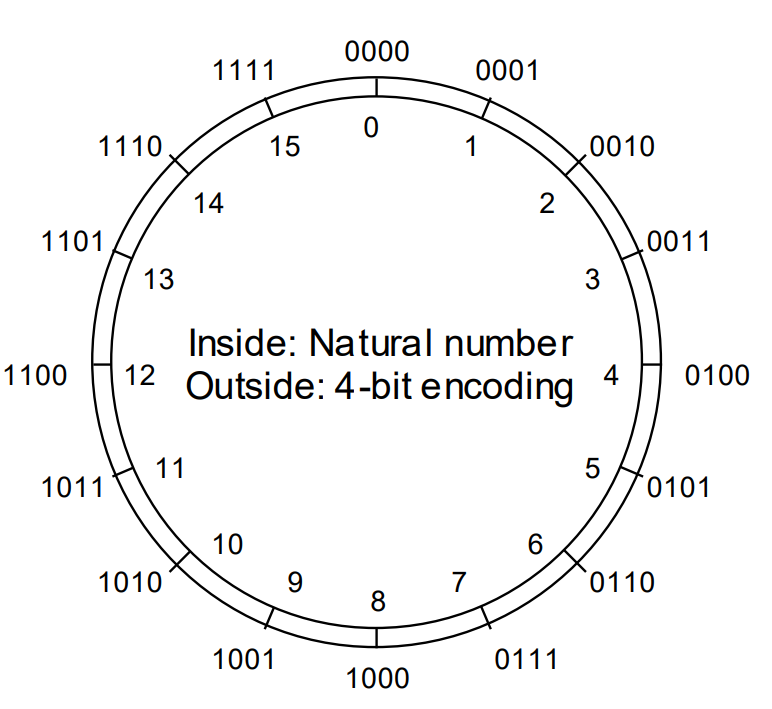
2s-complement representation of 4 bits inteder: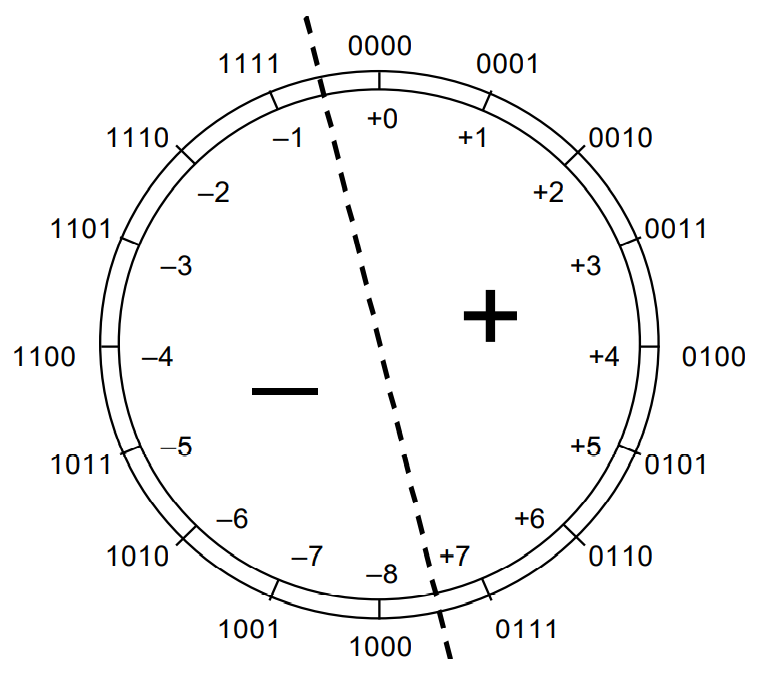
note that h(-5)=b(1011)=-(2)^3+2^1+2^0
fixed-point 2’s-complement numbers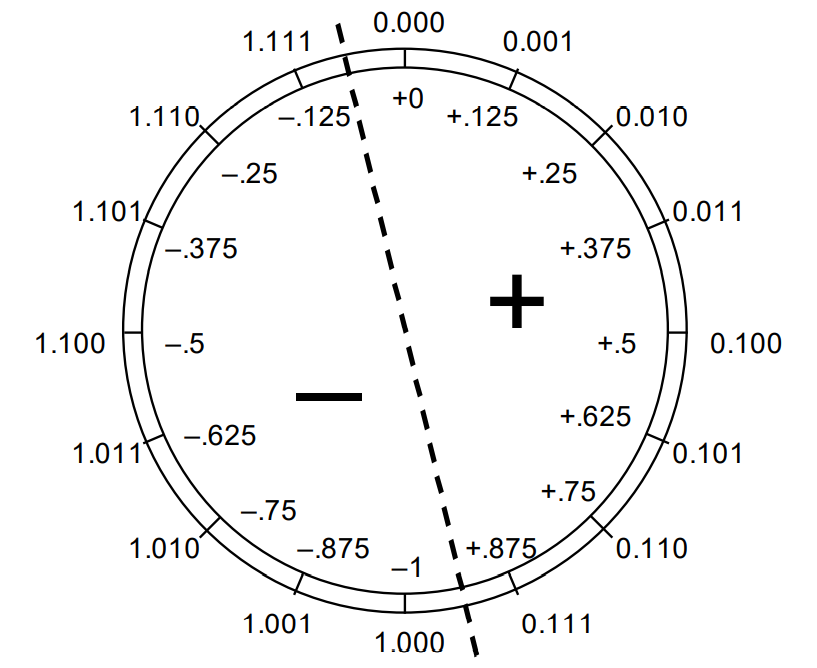
multiplication
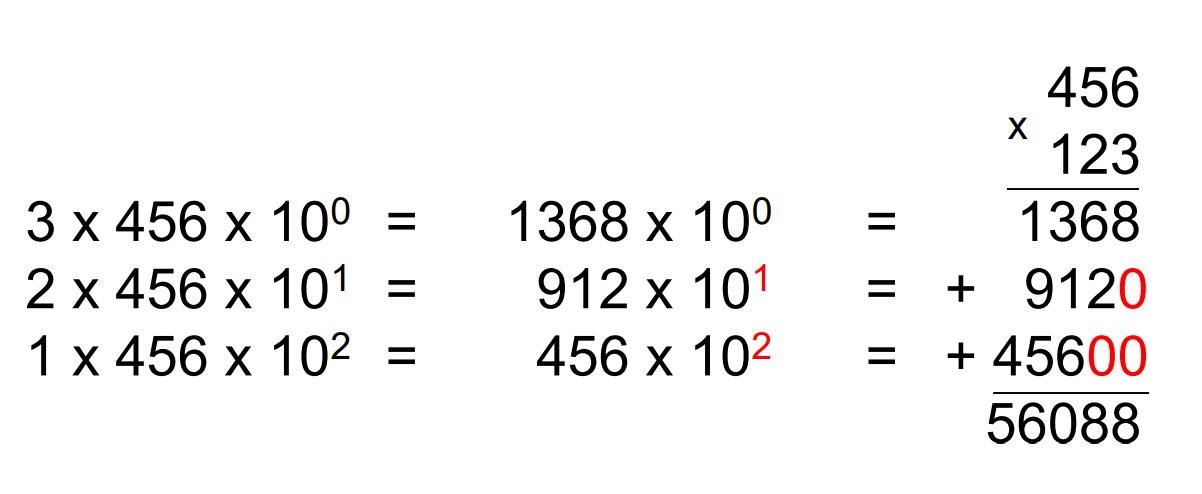
hardware multiplication
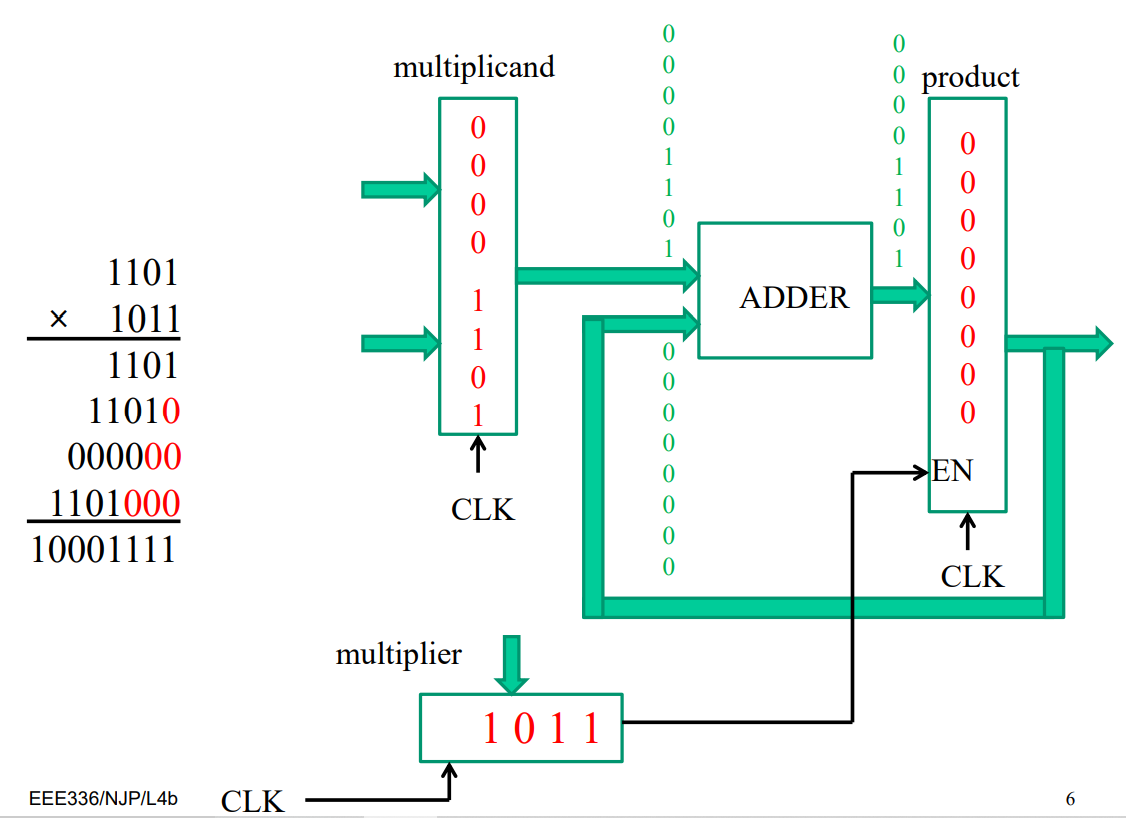
multiplicand will delay 1 bit after each operation like 0000 1101→0001 1010
multiplier will shift to right after each step like 1011→101.
product will save results output from adder. but changing process will be cancled if the most right side digital number in multipier is “0”.
combinatorial multiplication
2-digit number A=(a10+a0) B=(b10+b0)
AB=(a1b1)00+(a1b0+a0b1)0+(a0*b0)
Booth’s Algorithm
the equation cna be writen as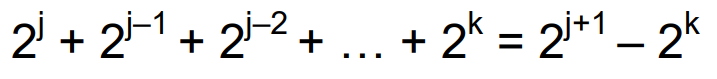
for example the euqation 43*12 can be explained as
1 | 43 = 00000101011 |
the relationship between multiplier and operation is
| bits | operation |
|---|---|
| 10 | subtract |
| 01 | add |
| 00/11 | nothing |
Week6
for A%B=C……D,
A is dividend
B is divisor
C is quotient
D is Remainder
for binary division, comparetion is the only thing need to do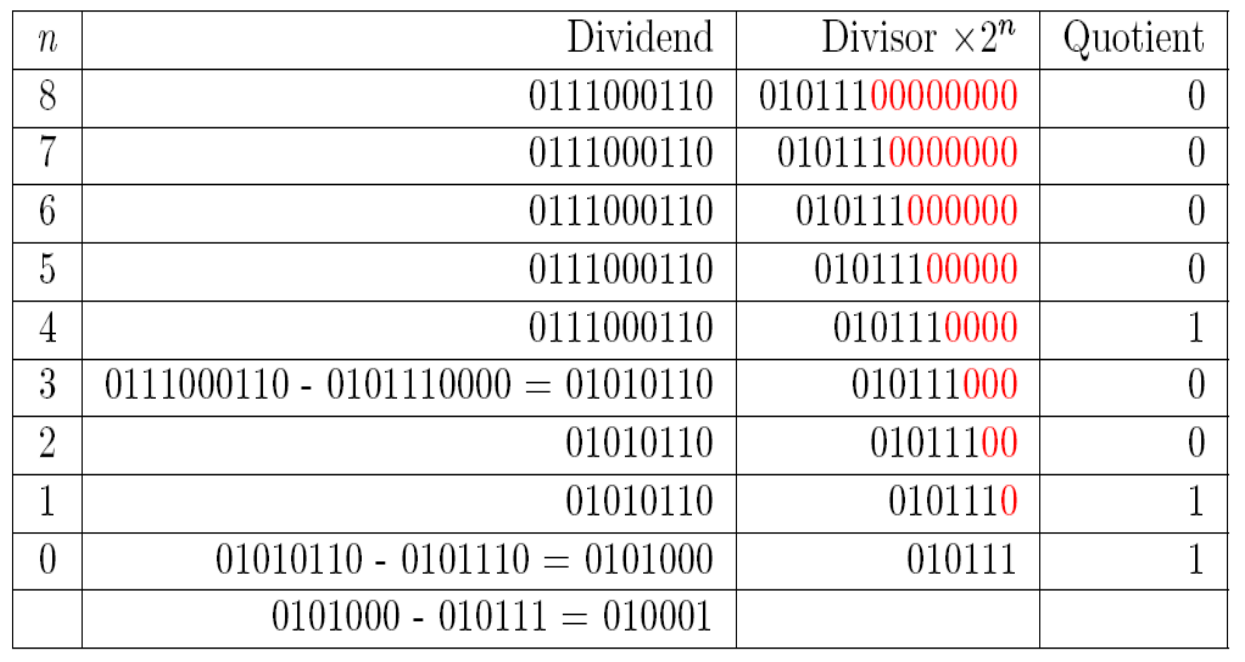
and its implementation is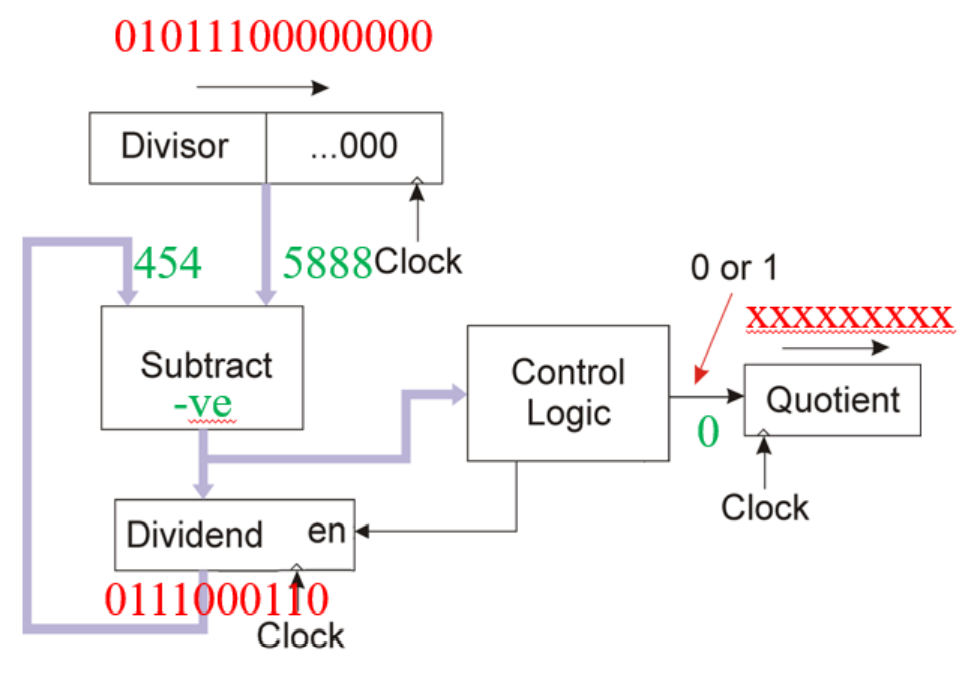
non-restoring/restoring division
restoring division: the dividiend will turn into previous value if result is negative
non-restoring division: don’t restoring the value if result is negative
the sign of operation is inversed with divided’s signal (“-“ if divident is positive and “+” if divident is negative)
if result if negative, ouput 0; if result is positive, output 1.
example: 456/23 by non-restoring division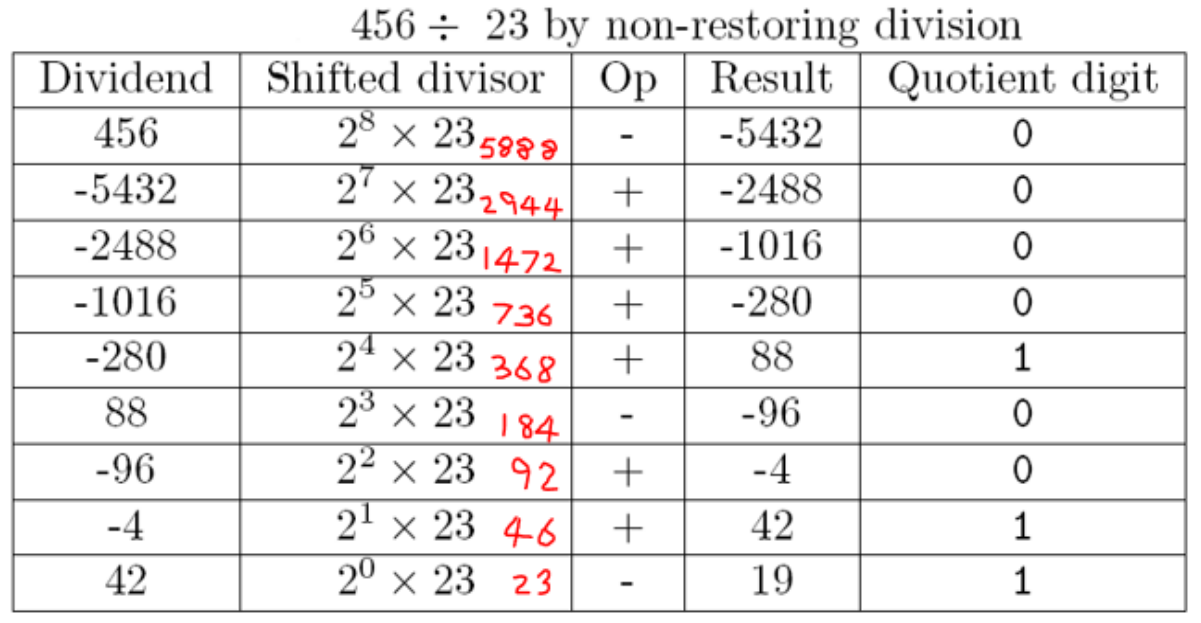
floating point
the value of point numbrt can be explaination as m*2^e, where m is mantissa and e is exponent
The IEEE-753 floating point number can can be formulated as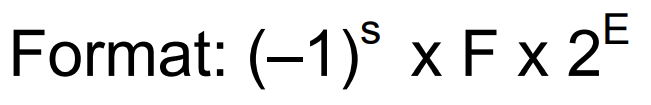
with 32 bits and 64 bits these two types
value in exponent will have a bias which bigger (127 in 32 bits and 1023 in 64 bits) than what we expected
example: turn -93.625 into 32 bits
- 93.625=1011 101.101 in binary
- it = 1.0111 0110 1 *(2^6)
- in 32 bits, it have 127 bias. Hence exponent=6+127=133=1000 0101
- remove this first “1”, get 0.0111 0110 1, hence 0111 0110 1 is fraction
- it is a negative number, hence sian bit =1.
therefore, get 1|1000 0101|0111 0110 1000 0000 0000 000 (23 bits)
Week 7
Memory resources
normally instructions are stored in main memory as a program and decode them when programe is required.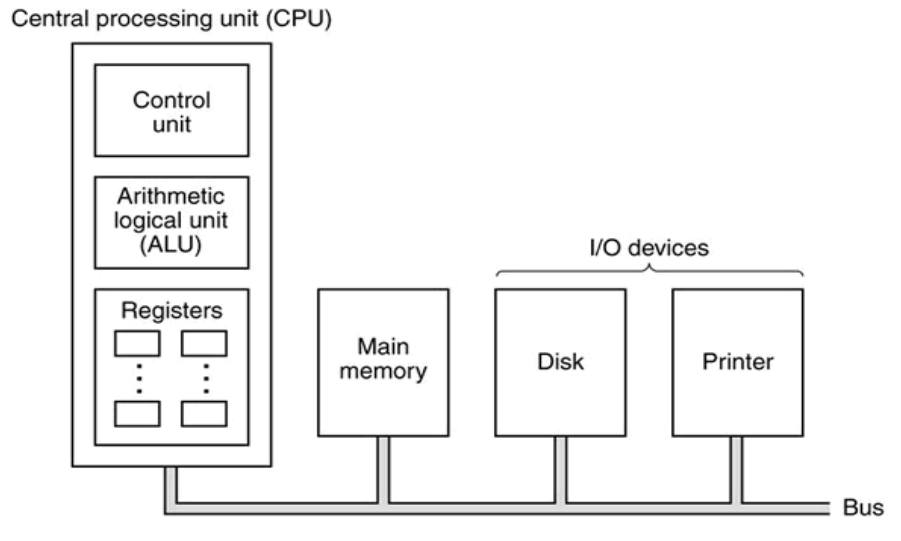
the address of each lines of programe is counted by a program counter (PC) which can count and load new addresses from status flags.
MIPS processor
MIPS is a Reduced Instructure Set Computer(RISC). it have 32 registers which have 32 bits wide for each, for byte addressing.
A MIPS word is 32 bits or 4 bytes but giving 2^30 memory words.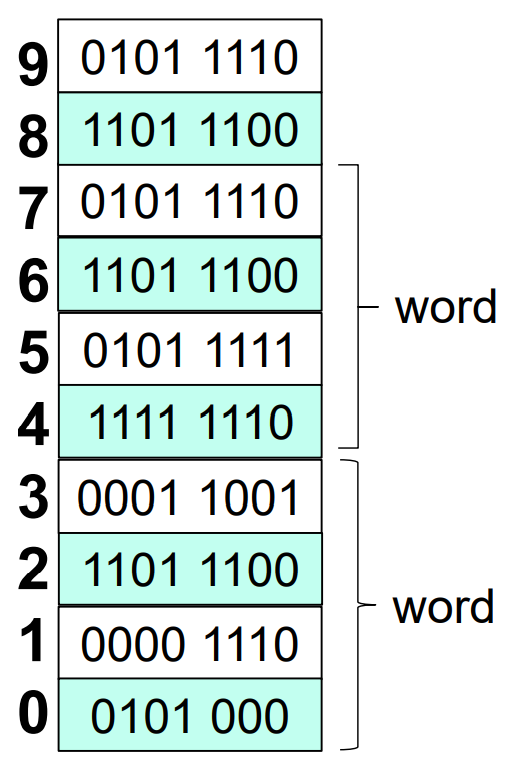
big endian: the most byte will stored in lowest address.
little endian: than least byte will stored in lowest address.
three ways have been developed based on MIPSformat
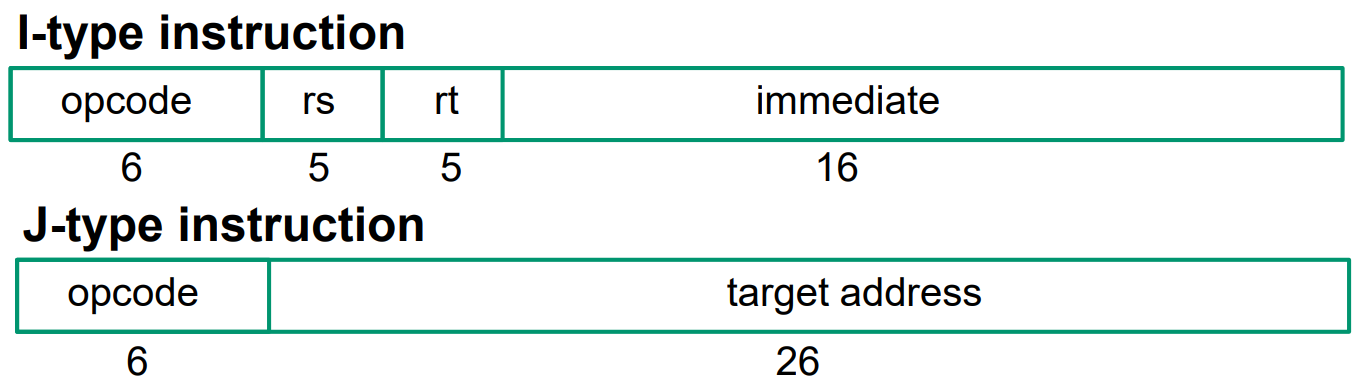
MIPS example
op: opening code
rs: register source
rt: register traget
shamt: shift amount (is not applicable when is 0)
immediate: value of offset
I-type: fast way to load a register and dont need extra memory refrence to fetch operand. but only constant can be supplied and is limitied by bit numbers as well.
example: addi $1,$2,20 : $1=$2+20
R-type: small address field required, shorter instructions possible and have a very fast execution. useful foe frequently operations like loop. but the number and space od address have all been limited.
example: add $3, $4, $5 : $3=$4+$5
Intel X86 Architecture
If the sort of instructions are increasing , a BIU can greatly control them.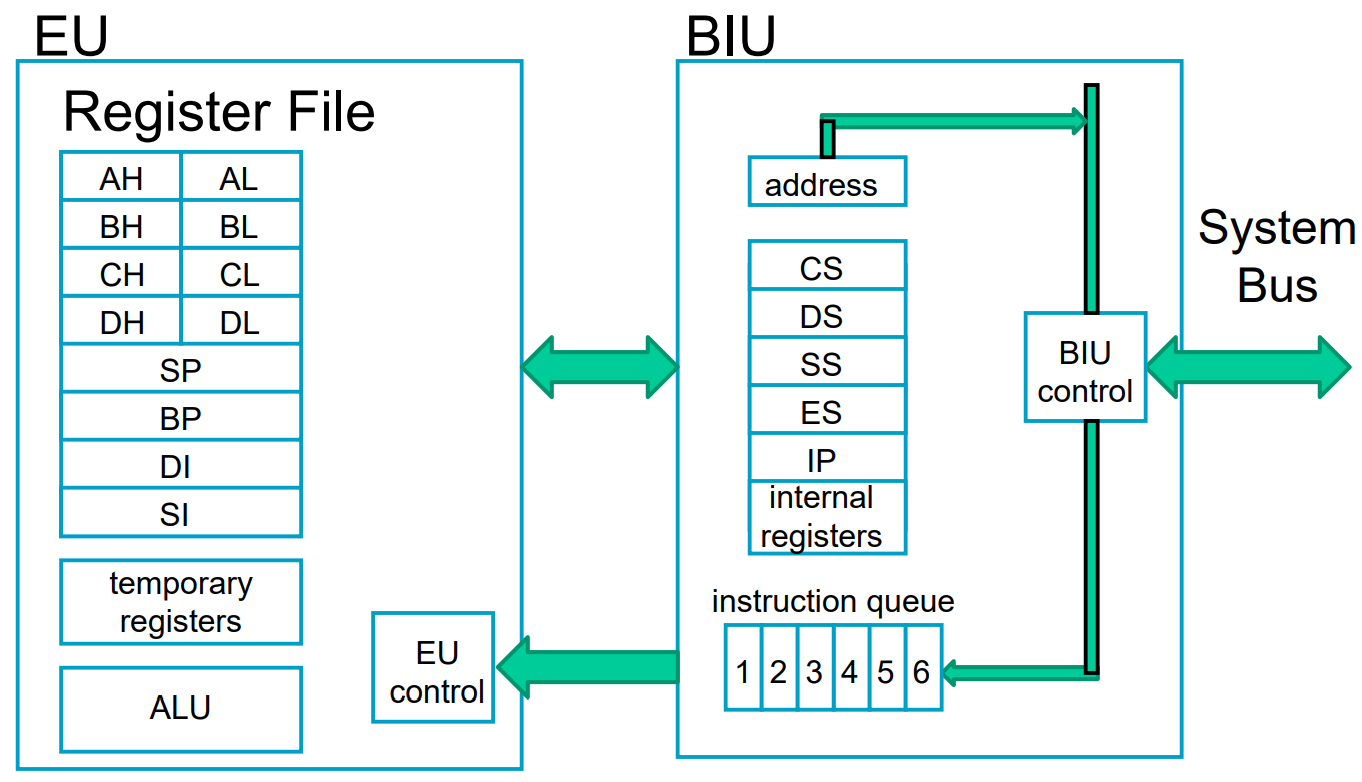
where EU is for executing instructions,
BIU is for fatching instructions, reading operands and writing results
however, although X86 is a 16 bit controller but have a 20 bits register.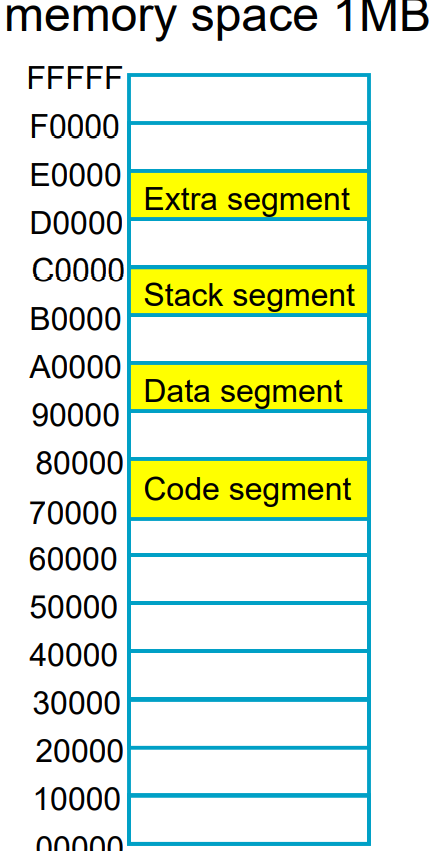
each segment represents a 64k block of memory, which is combined with an offset address in instruction pointer(IP).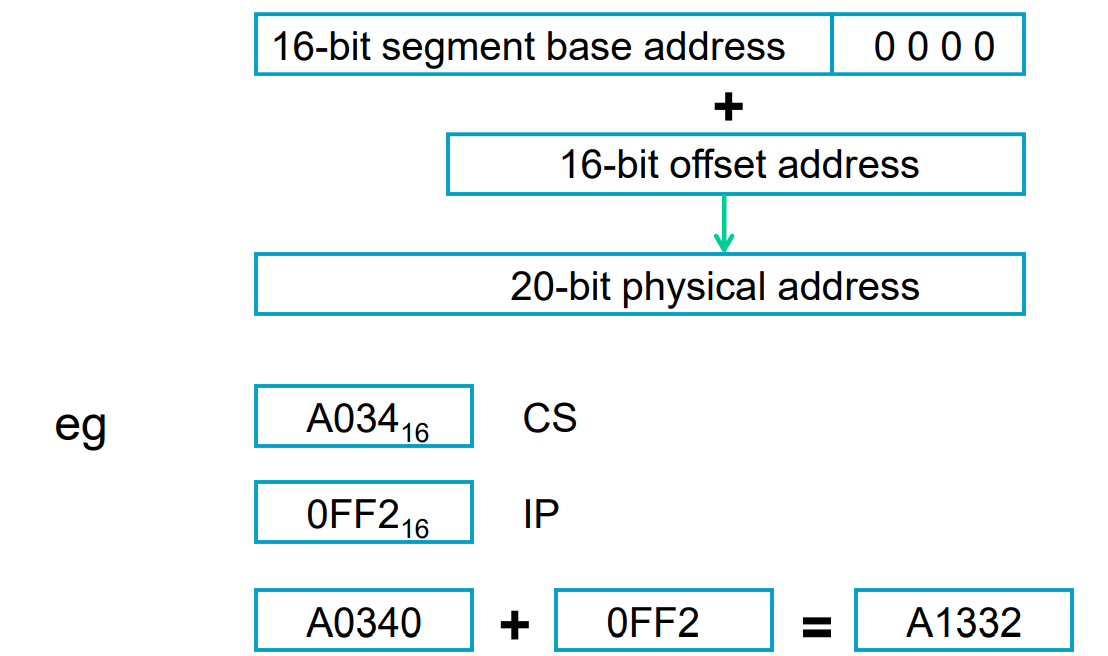
Pipeling instruction: the execute and next fetcj have overlapped to reduce the time used on a cycle
Von Neumann Architecture: single interface for both data and instructions. but an instruction fetch and data opeartion can not occure at the same time cause they share a common bus
Harvard Architecture: seperate the interface of data and instructions. the program memory accesses and data accesses can operated paralllel.
Week 8
register control
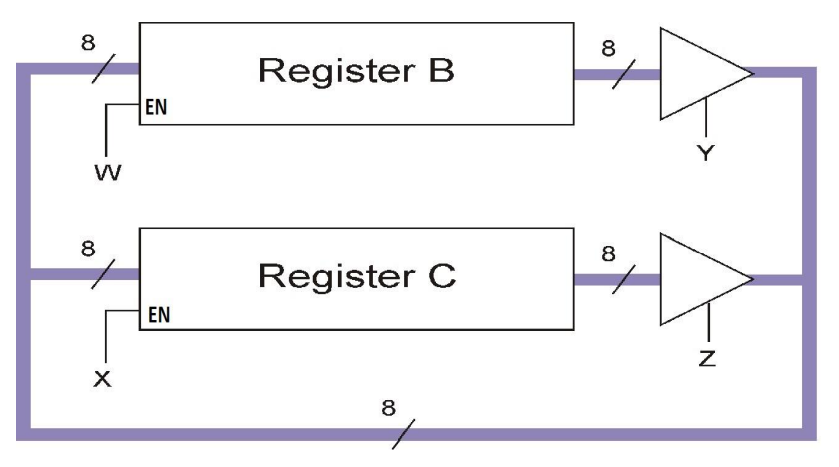
four single bit X,Y,W,Z can separately control input and output for both two registers.
data from register B will move to register C if w=0,y=1,x=1,z=0
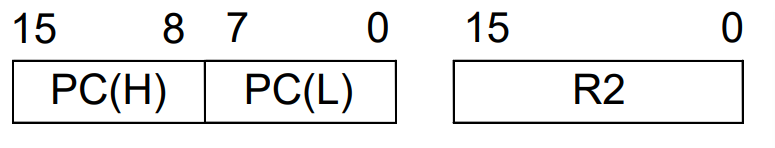
PC,R2: denotes a register
PC(7:0),R2(1),PC(L): denote a range of register
R1←R2, PC(L)←R0: denotes data transfer
R3←M[PC]: specifies a memory address
like R1←R1+R2 add the results to R1 for additoin of R1 and R2
X.K1: R1←R1+R2 if X.K1=1, R1 will be placed the value of R1+R2
(normally, X.K1 will be the enable port in register)
Week9
Stack
the stack is allocated in main memory and operates as a last in first out block of memory
the flow control istructions change the PC constant with three order:
HALT: places the processor in an idle state
JUMP: change the PC content to a pointed address
CALL: like jump but CPU must remember the return point and return after finishing
the LIFO stack with two operations:
PUSH: puts value into stack
POP: Retrieves the last value that was pushed onto the stack
do not operate POP to a empty register or PUSH value in a full register
a stack pointer register (PC) can be used to allocate the final register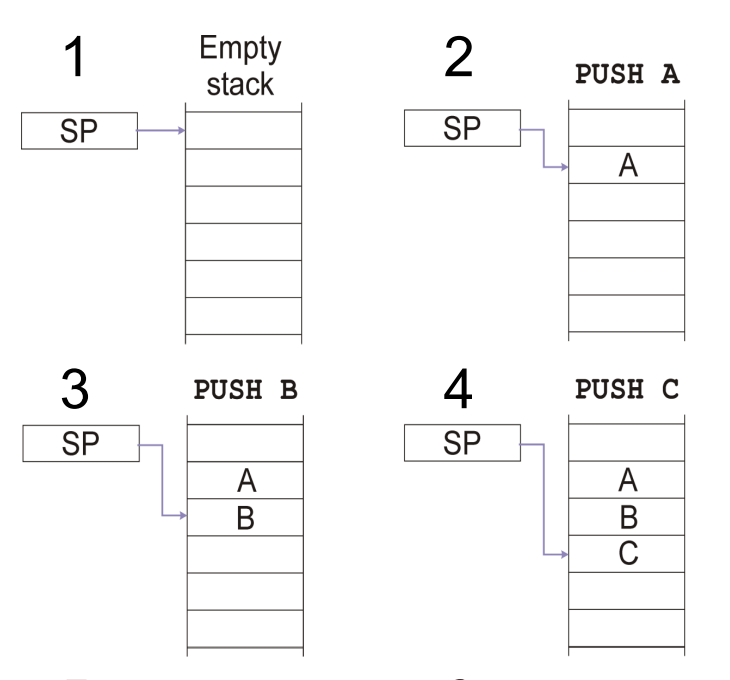
cache
cache is a safe place for hiding and storing things
CPU will first view cache when want read the memory. if it find the memory in cache, called cachehit, in opposite state, called cache miss and CPU will fins the memory from register and copied it into cache again
Direct Mapped Chache: each block is mapped to a single cache location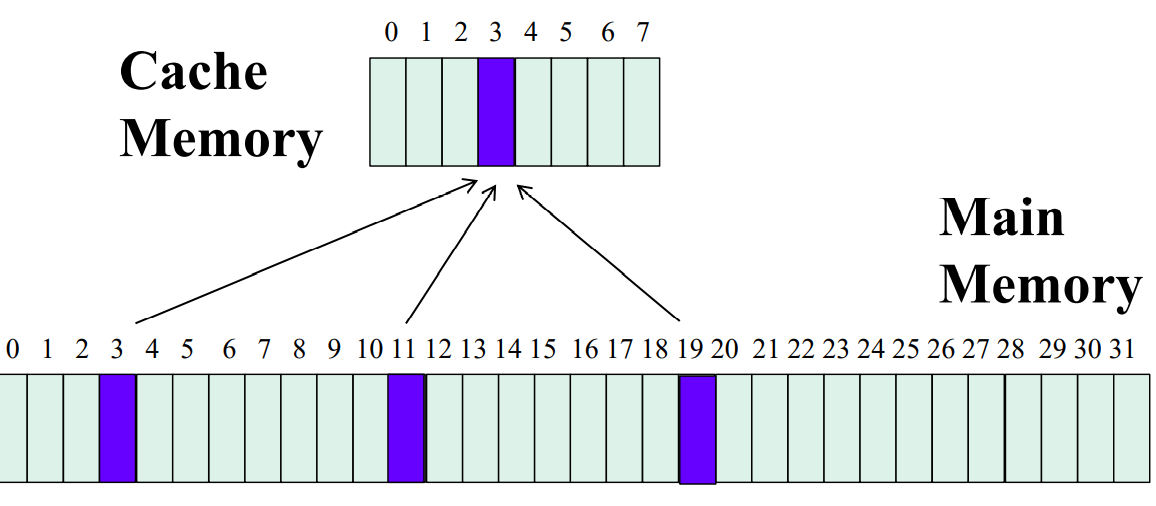
it is simple and easy for implementaion but have poor performance
Full Associative Cache: each block is mapped to any cache location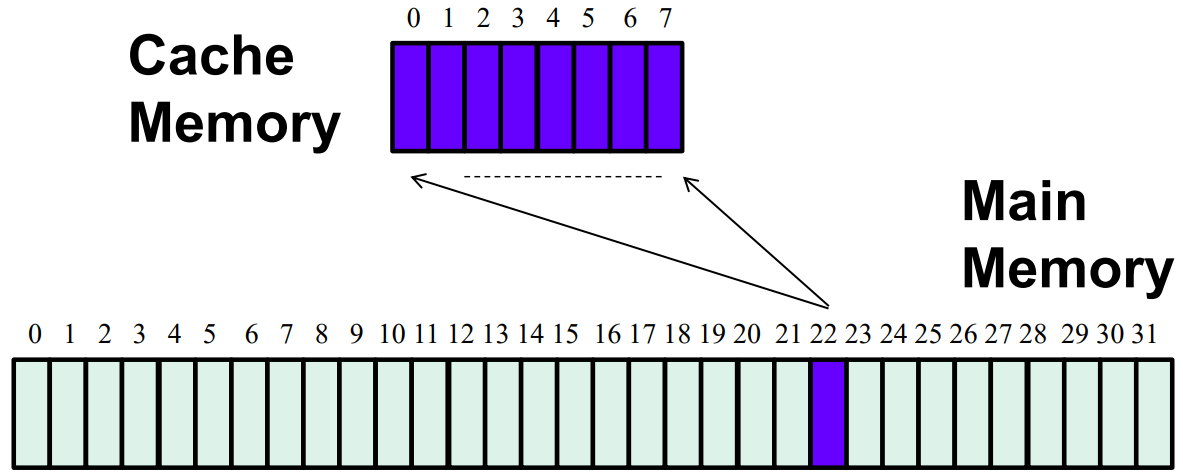
all memory block can be mapped but harder for implementation
Set Associative Cache: each block is mapped to any block in a subset of cache location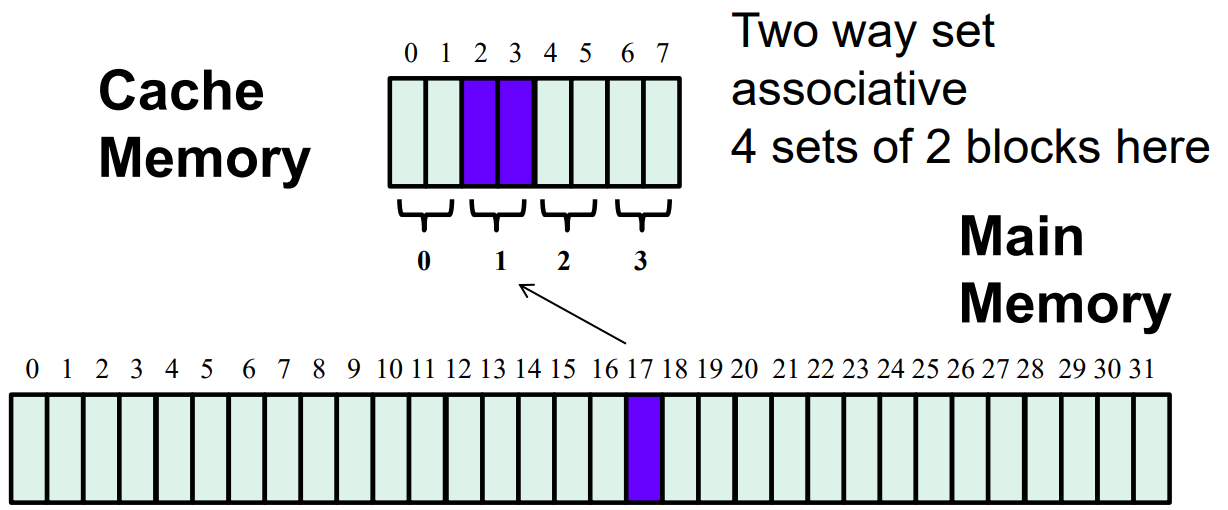
the best way
cache mapping

V: a valid bit to indicate if address contains valid data
TAG: determines which block of memory is in cache
INDEX: select block in cache
OFFSET: select a byte number got multiple byte blockes
for direct mapped cache: memory=TAG+INDEX
for full sccociative cache: memory=TAG+OFFSET
Week10
Digital filters
for transimiting and receiving analog signals, need to use ADC and DAC
Finite Impulse Response (FIR) Filter
consider a 4-point averaging window and get a stable curve results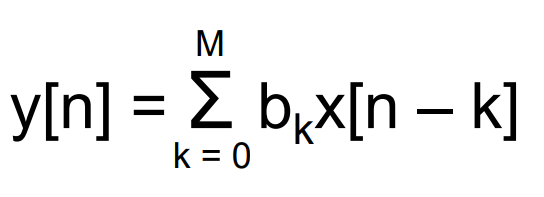
the implmentation of builidng blocks are contained with Multiplier, Adder and Unit delay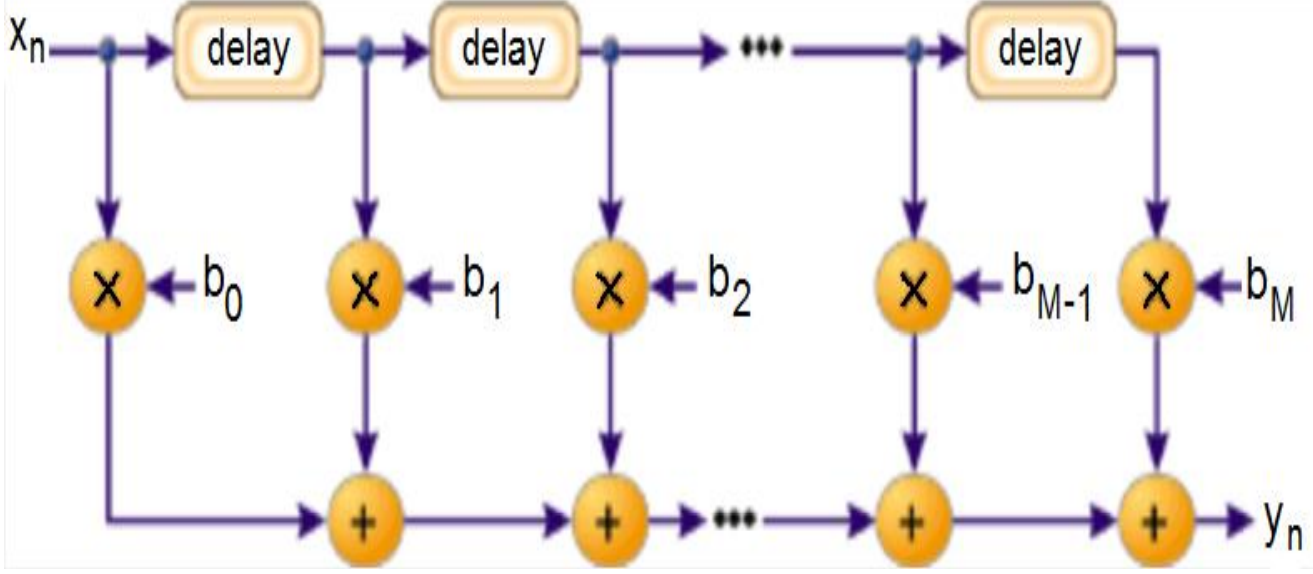
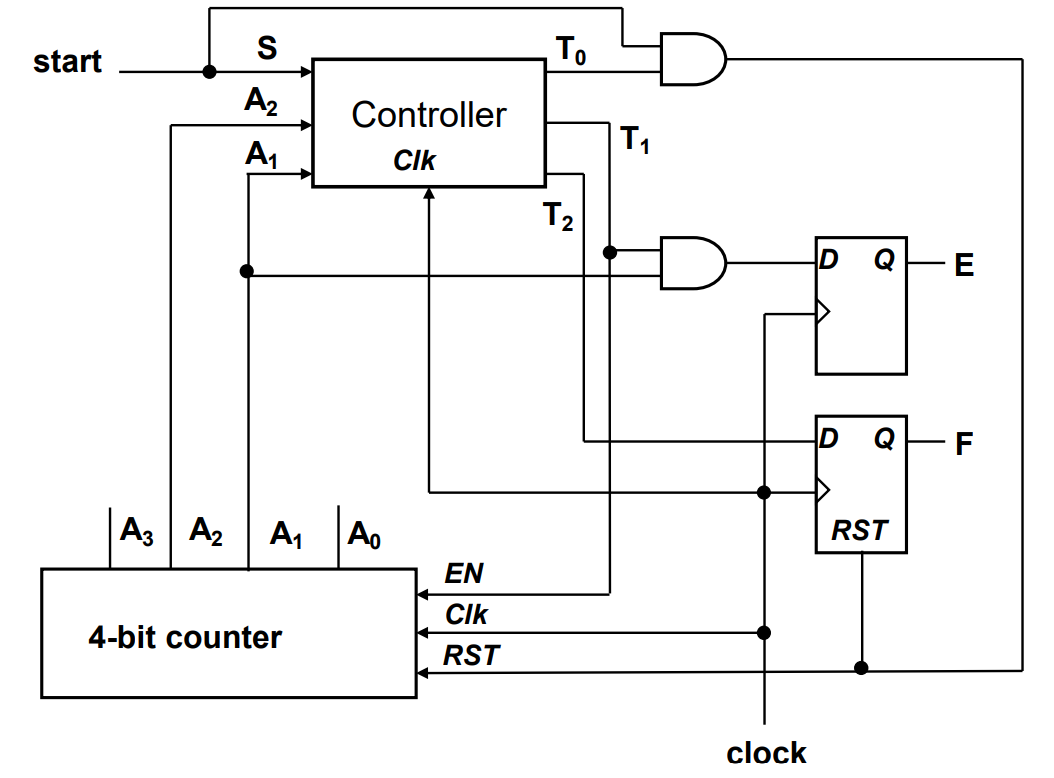
Algorithmic state machine chart
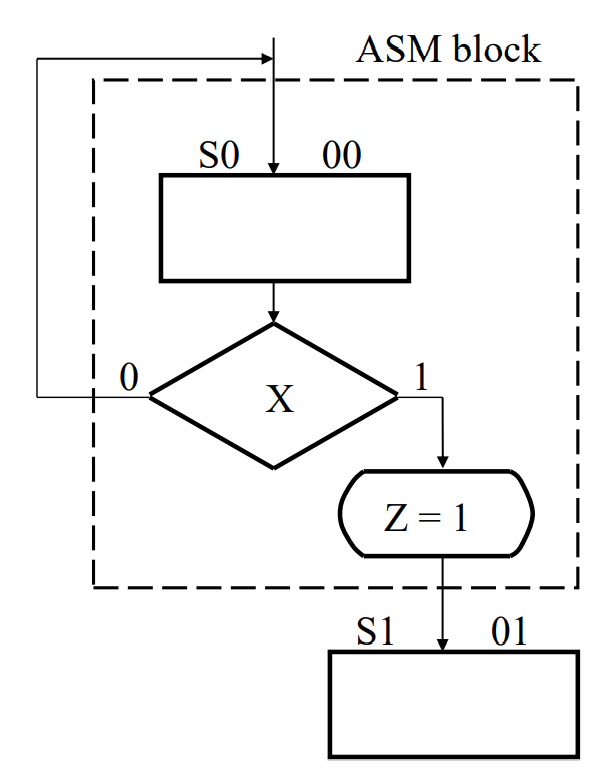
state box: unconditional, moorly output which only depends on current input values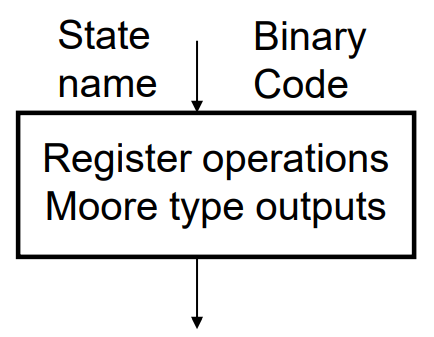
decision box: conditoinal, mealy output which not only depends on input, but past output results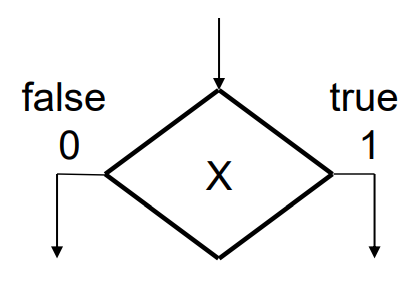
decision box can have multiple outputs depends on decisions made
conditional box: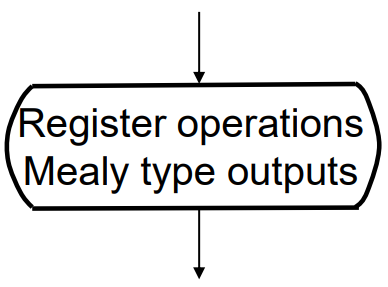
an ASM box must consists of a state box, decision box and conditional box
usually start with state box and end before the next state box
implementation
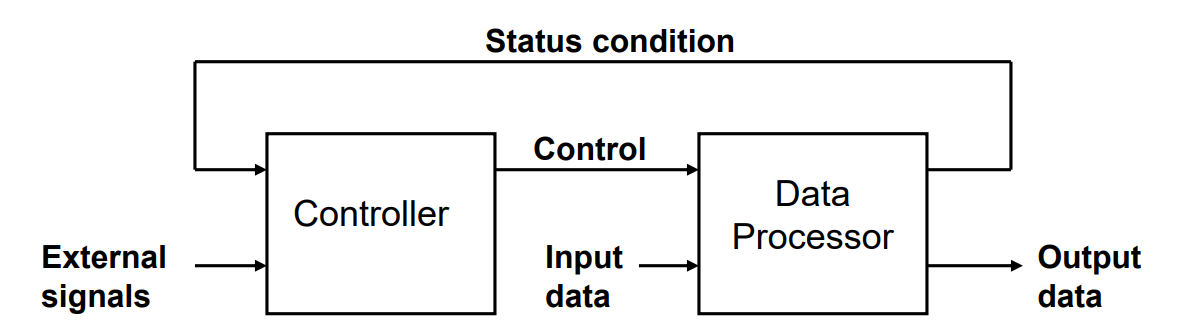
controller logic can obtain condition box and state transition
data procesor can contain operations described in state box and conditoin box
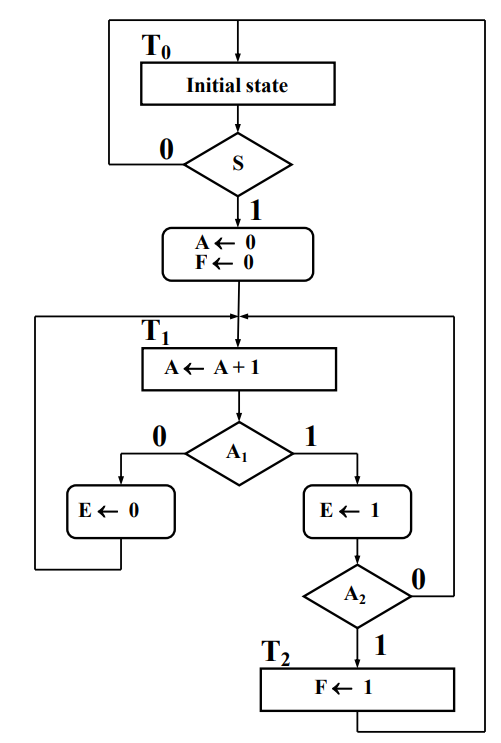
Topic 1
Unit impulse: 𝛿[n]=0 (n≠0), or =1 (n=0)
Unit step: u[n]=0 (n<0), or =1 (n≥0)
for a sinusoid:
𝑥[𝑛]=A cos(𝜔0 𝑛+𝜙)
𝜔0:Normalised frequency
𝜙:Phase delay
Normalised frequency in radians/sample:
𝜔0=Ω0⁄𝑓𝑠,
where Ω0=2𝜋𝑓, is the real angular frequency, fs is sampling frequency
if angular frequency=𝜋 rad/sec, frequency=𝜋/2𝜋=0.5Hz
if a 1 Hz sine sampled by frequency of 10Hz, 1/10=0.1 cycle per sample
angular frequency = 2𝜋*0.1 cycle per sample =0.2𝜋 radians per sample
Important properties of sequences:
Linearity: y[n]=T{x1[n]+x2[n]}=T{x1[n]}+T{x2[n]}
Time invariance: y[n-k]=T{x[n-k]},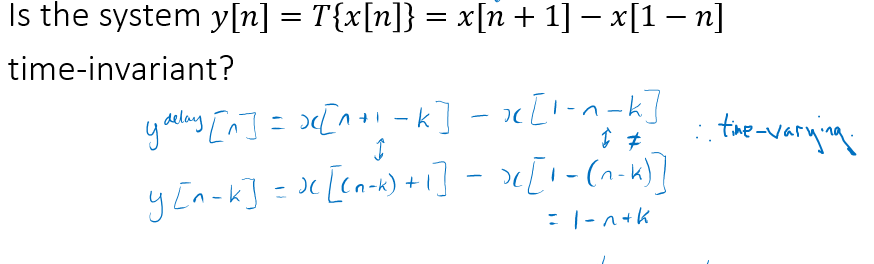
Stablility: input and output is bounded
Causality: y[n0]=T{x[n<n0]}
note: Linear and time-invariant = LTI system
Linear constant coefficient difference (LCCD) equation:
LTI systems can be described by a difference equation of the form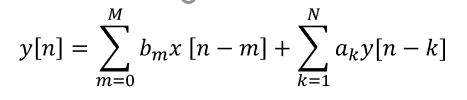
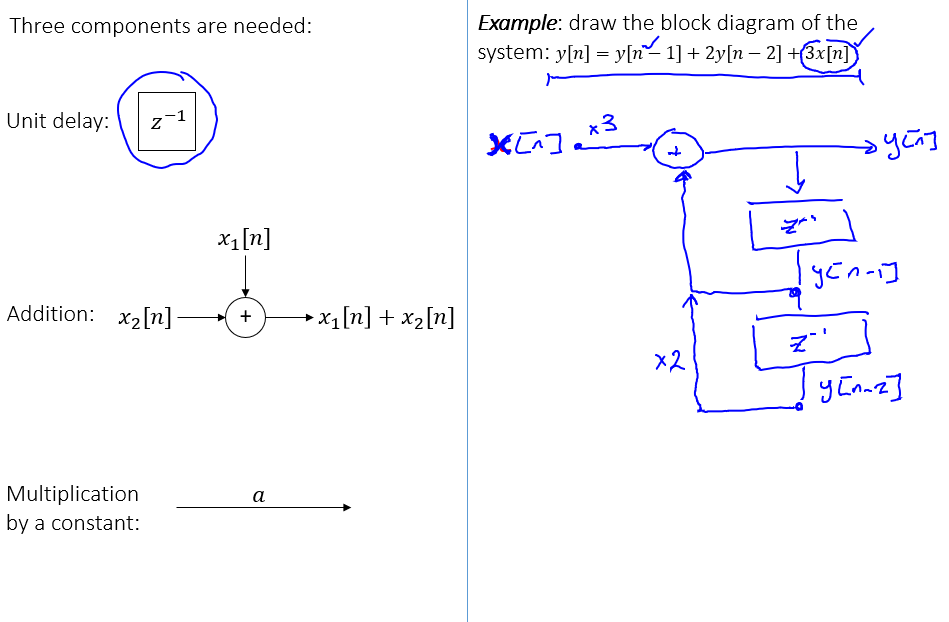
impulse response (can be explained by convolution)
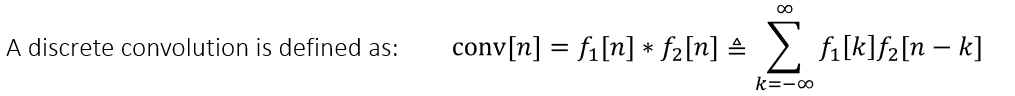
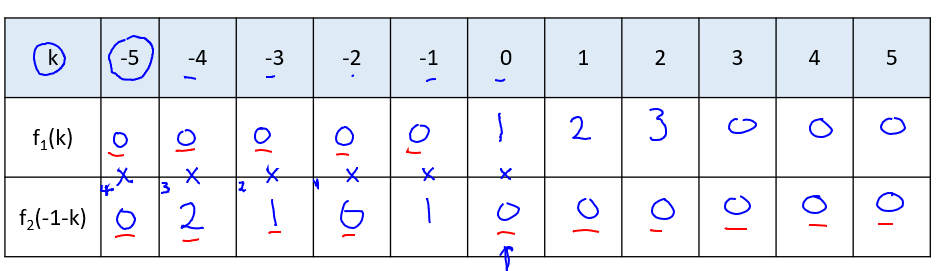
where n in figure is a random constant value,
assuming n=-1, f1[k]=[1,2,3], f2[k]=[1,0,1,2]