FPGA程序复现
使用Verilog实现Conway生命游戏逻辑并使用VGA和鼠标显示并控制
基于BASYS3板,Vivado 2015.2版本开发
logbook过程记录
总览
自2023/05/06 - 06/08,历时一个月。由于准备不足加其他事情耽搁,导致多花了很多时间。
如果没有反复推翻原有设计重新编写逻辑,应该可以在半个月内完成
最终本项目可以允许用户使用Ps2鼠标左键添加新的cell,右键删去cell,中键拖动画布
可通过VGA显示画布上cell信息,以60Hz刷新
FPGA上的上下键可以放大/缩小画布,左右键增加/减少画布大小,并通过左边第二个switch选择调整的是x轴或y轴
画布的行/列数量会在7-segments上显示
推动左边第三个switch可以开始/暂停运行,最左边switch可以用来reset整个系统
系统可以在VGA显示下最大1024*512大小画布以60Hz运行,如果不用VGA显示理论上可达到3051.76Hz(100MHz CLK)
但相对应的,LUT占用也达到了50%左右
总系统参数传递如下: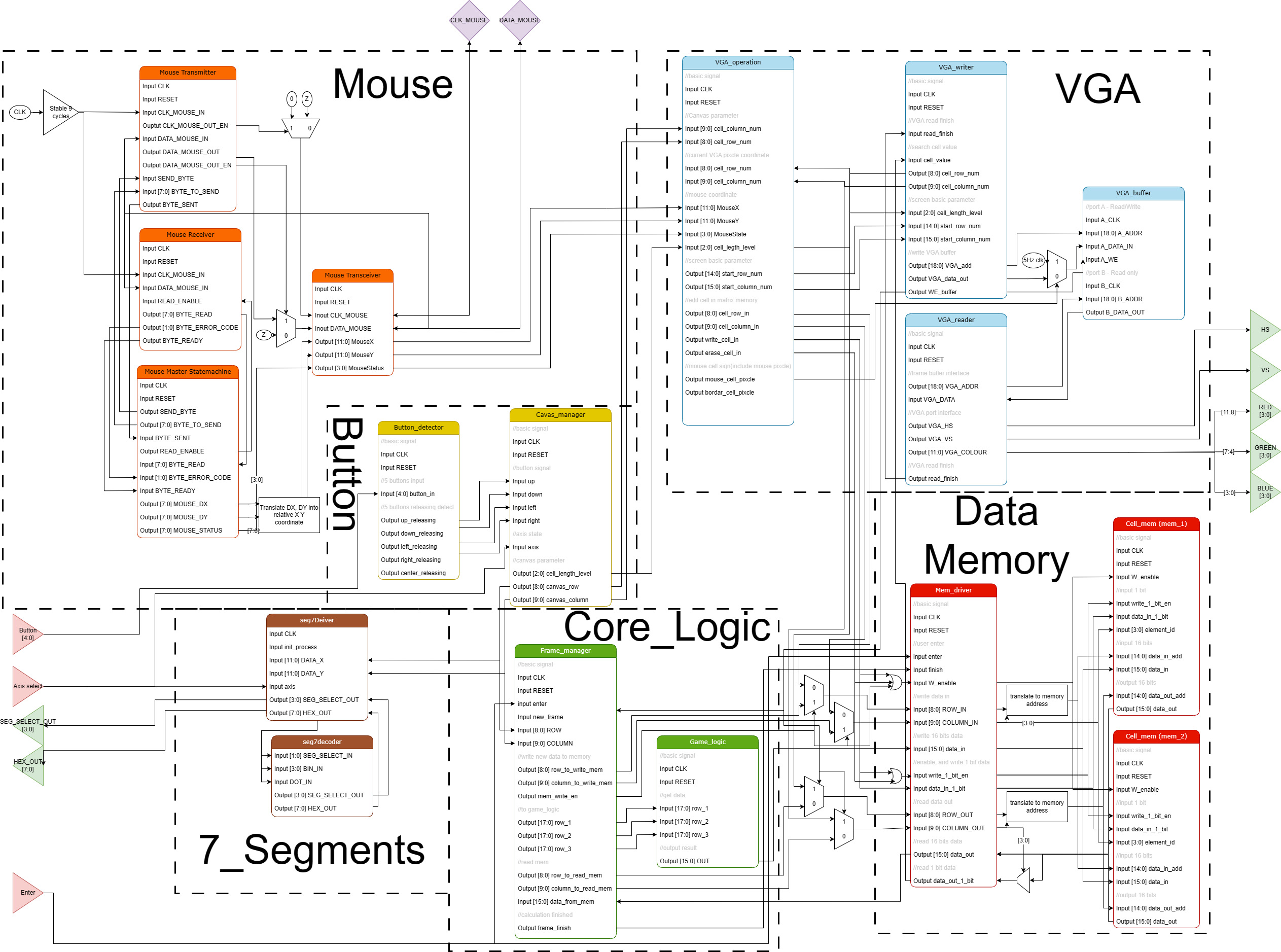
github代码:(https://github.com/ycen2111/life_game/tree/master/Verilog/LifeGame.srcs)
2023/05/06 (废弃)
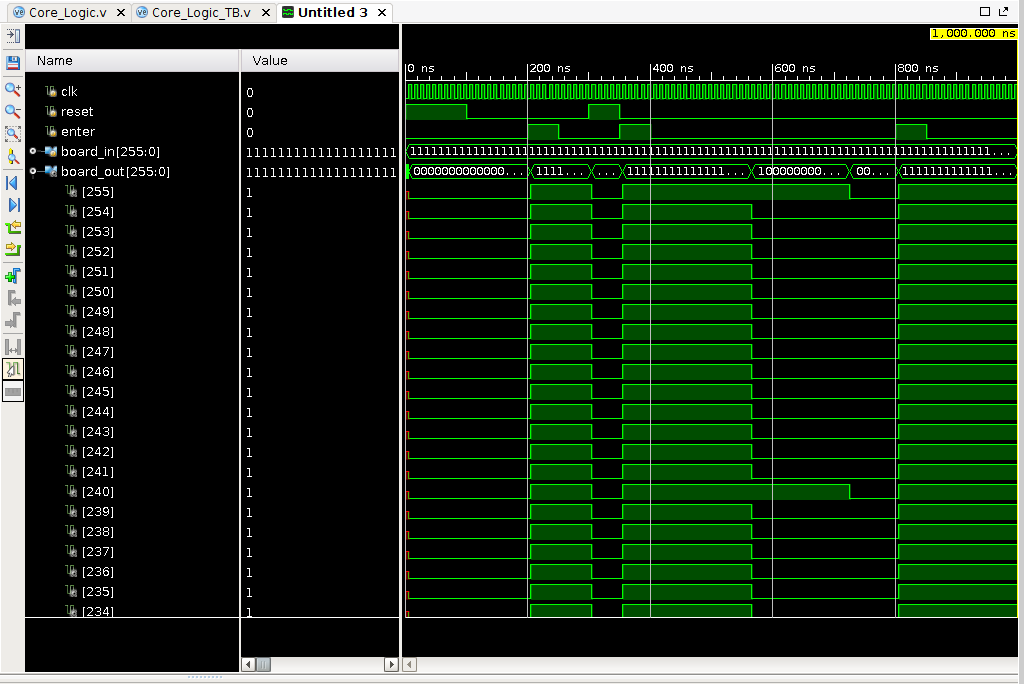
- 设计了核心逻辑Core_logic.v并配套testbench文件,可测试reset,enter,output,和正常运行功能。
- 已通过behavior simulation
Core_logic.v:
BIT_NUM: 长宽值的比特数,如长宽均为4,比特数为2
| port name | type | bits | comment |
|---|---|---|---|
| clk | input | 1 | clock cycle |
| reset | input | 1 | rset signal |
| enter | input | 1 | input new board figure |
| board_in | input | 2BIT_NUM2 | new board figure |
| board_out | output | 2BIT_NUM2 | simulated board output |
内部变量:
SIZE_SQUARE = |2BIT_NUM2
board[SIZE_SQUARE - 1:0] 为当前需要处理的图像,输出为board_out
next_board[SIZE_SQUARE - 1:0] 为board处理的下一次需要处理图像
past_board[SIZE_SQUARE - 1:0] 为保存的上一次图像,主要为neighbors判断下一次状态做准备
[3:0] neighbors [SIZE_SQUARE - 1:0] 为判断好的每个格子周围活着的cell数量,会在下一个cycle判断并存在next_board
主逻辑:
for循环遍历所有元素,判断是否为最上下左右,和四个角的位置,分9种不同的状态分析,存储在neighbors中
在下个个cycle根据neighbors中的值和past_board判断next_board
每个cycle都会将next_board赋值给board
如果为reset或enter,将其他值赋给board
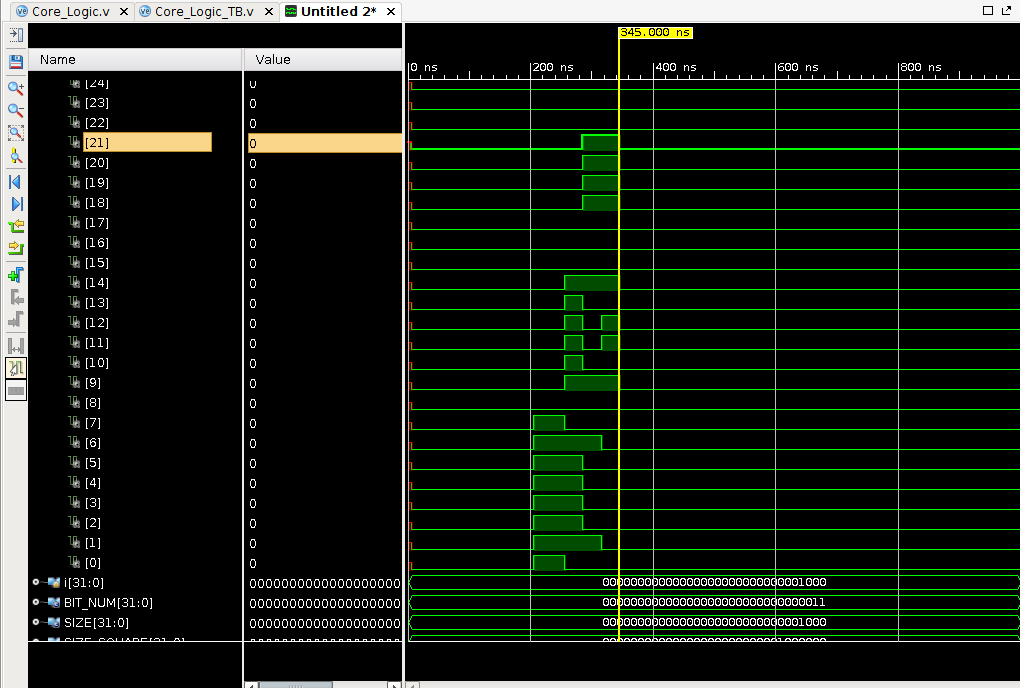
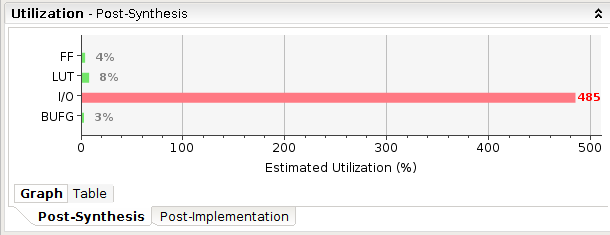
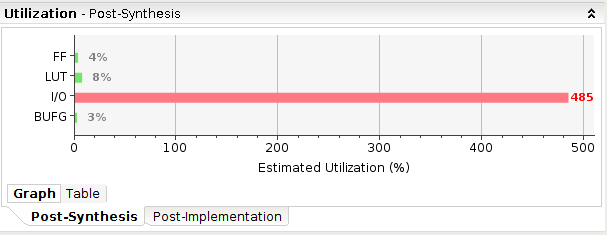
注:I/O过高是因为所有board_in,board_out直接输入导致
2023/05/08 (废弃)
- 新增分频模块
- 为core_logic增加pipeline分析 (core_logic_v1.v)
新增模块
最普通偶分频程序,输入系统clk输出分频lk
新发现问题
虽然可以综合16X16网格逻辑,但无法综合更大的逻辑(LUT占有率超100%)
改进方法
增加pipeline分析,每个posedge只会计算一行网格,在所有网格计算完成后输出finish信号并将next_board赋予board输出
改进结果
允许最多256X256网格分析(port最多允许10000000 bits array)并顺利综合
同时注意for循环不能将结束循环的值设置太大,即使像for(i=500; i=500+10; i=i+1)也会报错因为程序会认为循环数太多
2023/05/17 (废弃)
考试结束继续开发
复盘了之前的逻辑,发现大量的LUT浪费在判断neighbor数量的重复逻辑上,我们不需要如此快的运算效率
因此打算重写主逻辑,使用pipline来降低效率,同时增加可处理的数据数量
- 覆写游戏核心逻辑,以支持pipline结构
- 配置对应TB,确保综合结果有效
- 整个module都使用parameter管理常量,方便之后变动
逻辑解释
module名:Find_neighbors
假设同时处理NN个数据,
input:cell_in (N+2)(N+2) //1-D 数组,左上角数据为最低位
output:cell_out N*N
程序会接收需要处理的NN marix和额外围绕在这个matrix外一圈的数据,统一得到核心NN元素的neighbor数量
如果一个核心N*N元素已经是角落和边上的数据,在它之外的数据会直接当0输入 (归一化)
数据轨迹
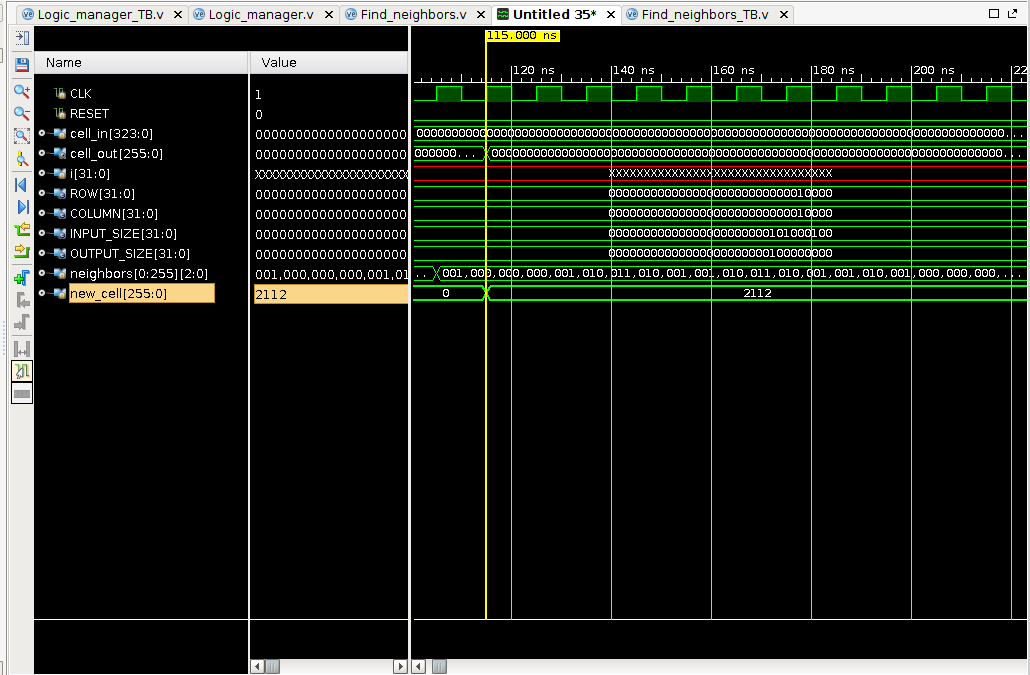
input -> cell_in -> neighbors -> new_cell -> output
从cell_in -> neighbors和neighbors -> new_cell都为时序逻辑,所以需要2 cycles来得到对应的数据
结果
输入:cell_in = 25’b0000001110011100111000000;
2023/05/18 (废弃)
- 继续编写Find_neighbors配套上层调用逻辑
- 使用FSM控制整体逻辑
- 编写配套TB,确认综合可用
核心逻辑
module名:Logic_manager
input:enter信号,当前matrix需要的ROW,COLUMN,新输入的点的row_in,column_in值
output:未定,暂时输出cell_out
curr_cell,next_cell[][]:主要存储各cell状态的2-D数组
FSM状态:
IDLE:初始化状态,如果收到RESET就会回归此处。初始化next_cell。如enter为1则转ENTER,否则转OVERWRITE
ENTER:更新个别cell状态。如果enter为1则将next_cell[row_in][column_in]赋值为1,否则转OVERWRITE
OVERWRITE:将next_cell的值赋给curr_cell。由于是2-D matrix所以要很久。之后可以根据空闲资源加快此效率。完成后转RUNNIGN_1
RUNNING_1:管理Find_neighbors pipline的前两个状态。对Find_neighbors的控制分三步进行:
第一步,只有input没用output,此步有2 cycles
第二部,同时有input和output,此步持续到所有data全部输入
第三步,只有output没用input,此步有2 cyclesRUNNING_1管理所有输入并标记可以输出的时间点。举个33核心数据(55总数据)例子:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 如果每次输入Find_neighbors数据是4*4数据,第一次会输入0到18这个正方形内数据,下一个cycle输入1-19正方形数据(因为这是最少的完全包含核心数据的方法),之后类推是5-23,6-24数据。
RUNNING_2: 管理Find_neighbors pipline的最后一个状态,接收所有数据后转回OVERWRITE
未完成目标
- 暂停功能,即把程序在完成一次运算后暂停的能力
- 在开始运算后还能不经过RESET enter新数据的能力
- LUT占用超出预期,需要调整
结果
此处的X为未使用的占位内存,可以在大小需求不大时节省运算资源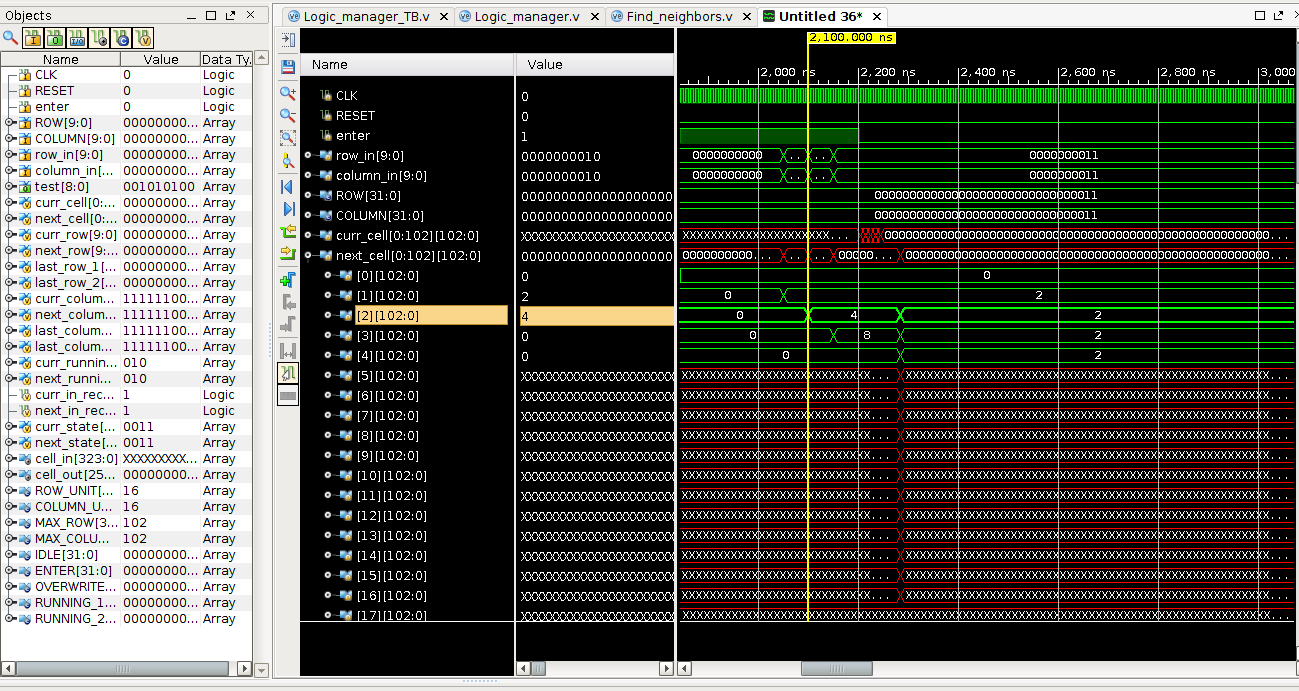
过高的LUT,问题出在generate block赋值不严谨,需再次调整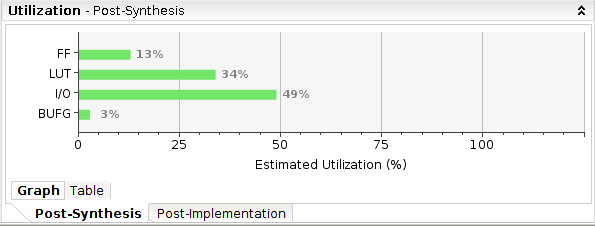
2023/05/19
- 理解VGA端口工作原理与设置
- 规划VGA数据传输方式
VGA原理
VGA主要还是sweep的方式逐行逐帧更新屏幕
| 端口 | 作用 |
|---|---|
| CLK | 时序信号 |
| HS | 水平信号,可以粗粗理解为列的enable |
| VS | 垂直信号,可以粗粗理解为行的enable |
| R[7:0] | 红色,VGA端口为相应的模拟信号,下面同理 |
| G[7:0] | 绿色 |
| B[7:0] | 蓝色 |
总体来说,当HS和VS给出信号后,VGA会自己读取相应时间下对应的颜色,并输出到屏幕上。
VGA会逐行读取,直到完成一帧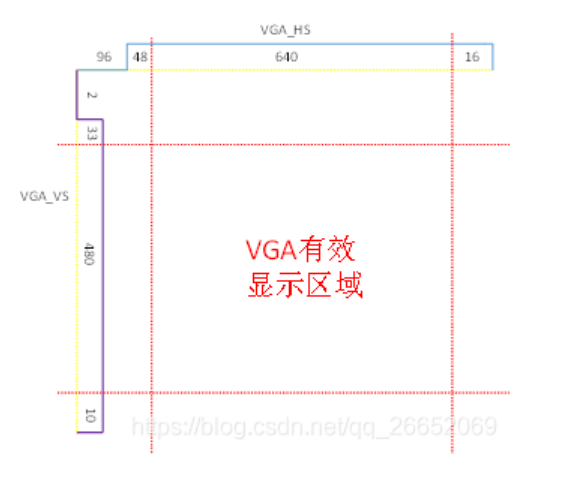
已上图来说,HS在96 cycles后会变高电平,VS在2 cycles后变为高电平,
但只有在HS和VS都在有效显示范围内,才会读取当时的颜色并输出
如,HS=96+48, VS=2+33时才会按当时输出的RGB颜色输出第一个点
传输规划
- 由于在真正VGA输出前有一段空闲时间,可以利用这段时间更新显示内容
- 所以可以初步计划在VGA显示的时候计算下一步的cell,并在上一帧更新完之后再将新的图像信息输入VGA
- 这个项目不会用到太多颜色,应该双色就可以解决。所以显存或许可以定为480X640数组,如果需要多种颜色就之后再说
- 并且由于显示器最大也只有480X640像素,总画布(cell数)不可能太大,导致1-D数组也可以完美记录所有数据,所以计划还是Logic_manager内cell变换为1-D数组,这又会加快运行效率(不必考虑2-D数组复杂的赋值)
总之,昨天有一部分又白写了,早知道先看这一块了 :(
2023/05/22
又出问题了,昨天新写的代母估计又要修改
先说问题,大概率cell的数据需要存到memory内,否则LUT占比巨大(仅 32X32 cell 就占了57% LUT)
- 改进了原逻辑下的FSM流程
- 综合后分析波形并订正冲突
- 分析LUT占比过高原因
- 测试了memory和LUT记录数据后综合的结果
原逻辑改进
主要是更改了RUNNING_1的三步状态,删除了原记录pipline步数的变量,改为左移一个array
如:最开始为一个2bits array:[1:0] mark, 初始化为2’b00。如果有输入find_beighbors就赋值mark[0] = 1,并在下cycle一开始左移一位
如果mark内有位数为1则说明find_neighbors还在运算,否则说明运算完成
这个方法可以稍微节省一点点资源(但可读性大大下降 (尴尬))
综合冲突
将RTL综合后发现输出cell为X,反推逻辑发现是赋值造成的问题。curr_cell在default内是非阻塞赋值,FSM内是阻塞赋值导致冲突。前后统一后问题解决
此问题原因是更改逻辑时未完全更改所有变量。之后应该尝试使用search,可以此类错误出现概率会小些
同时发现LUT占比更加夸张,如果还保持16X16 find_neighbors会达到256% LUT占用。
查看schemetic发现基本LUT消耗在curr_cell上,此问题涉及数据存储的原理
数据设置与类型
verilog中可以用两种方法设置array:
- [5 : 0] array
- [0 : 0] array [5 : 0]
以上两种存储数据大小相同,区别在1.是直接存在LUT内,2.存在memory(BRAM)内。
1可以很方便的对所有数据统一处理,但问题在如果array巨大(如 4000+),那么会消耗海量资源(密密麻麻全是赋值比对的)。
2可以共用一套逻辑,但问题在覆写数据麻烦,需要一个个赋值
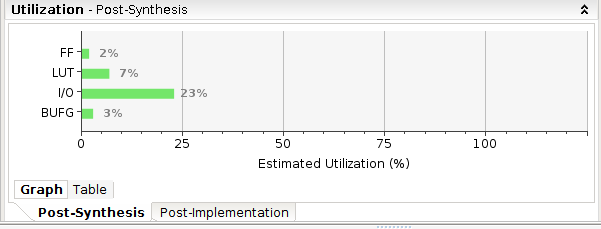
下面是分别用两种方法读取或写入数据的综合对比
[5 : 0] array
1 | module Cell_mem#( |

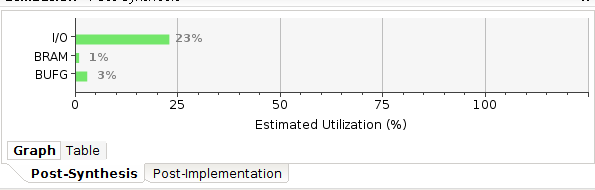
[0 : 0] array [5 : 0]
1 | odule Cell_mem#( |
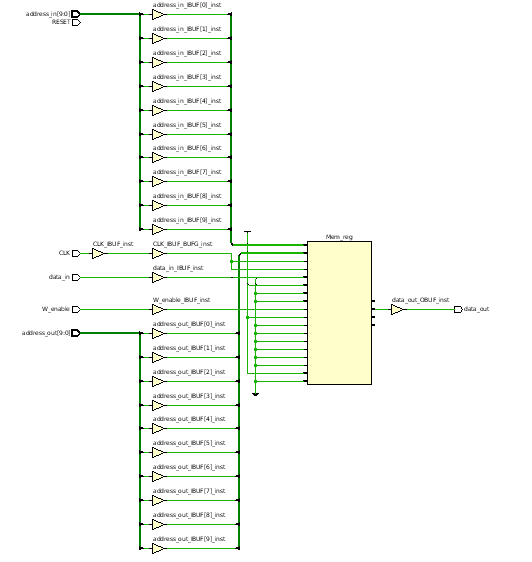
总结
后一种占用资源明显减少,结构也更简单
所以还是要更改find_neighbors驱动
现在暂时有两个修改方案,1.是memory每一行有8个数据(2-D数组),分别是一个cell周围一圈的neighbor,方便直接计算neighbor数量,但保存的数据会巨大
2.是保持原样每行1个数据(就是1-D数组),直接读取所有需要的cell。逻辑会更复杂,但应该更省心
2023/05/23
先说结构,最后打算采用16bits为一组的16列sweep读取计算方式
如详细编码方式之后编写数据传输时会解释,这里主要记录memory控制方法
需要注意的是所有memory都会有一个备用存储空间,用来暂时记录下一步matrix会显示的数据
- 编写memory读写逻辑
- 编写memory driver控制逻辑
- 通过testbench并成功综合
memory读写逻辑
存储memory:
reg [15:0] Mem [2 ** (MAX_ROW_BITS + MAX_COLUMN_BITS - 4) - 1 : 0];
每条数据存储16位,因为16bits为memory单block可支持最大bits
一共有MAX_ROW*MAX_COLUMN/16条数据
| type | bits | name | description |
|---|---|---|---|
| input | 1 | CLK | 时钟 |
| input | 1 | RESET | 复位 |
| input | 1 | W_enable | 允许写入 |
| input | [2 ** (MAX_ROW_BITS + MAX_COLUMN_BITS - 4) - 1 : 0] | data_in_add | 写入地址 |
| input | [15 : 0] | data_in | 写入数据 |
| input | [2 ** (MAX_ROW_BITS + MAX_COLUMN_BITS - 4) - 1 : 0] | data_out_add | 读出地址 |
| output | reg [15 : 0] | data_out | 读出数据 |
如果RESET, Mem会将自己覆写为”Mem.txt”内数据
如果W_enable,Mem[data_in_add] 会覆写为 data_in
无论何时data_out 都为输出 Mem[data_out_add]
memory driver逻辑
主要处理两件事,将输入的横纵坐标转化为mem的id,和控制两个memory各自读写权限
| type | bits | name | description |
|---|---|---|---|
| input | 1 | CLK | 时钟 |
| input | 1 | RESET | 复位 |
| input | 1 | W_enable | 允许写入 |
| input | 1 | finish | 一帧matrix计算完成 |
| input | [MAX_ROW_BITS - 1 : 0] | row_in | 写入数据的行坐标 |
| input | [MAX_COLUMN_BITS - 1 : 0] | column_in | 写入数据的纵坐标 |
| input | [15 : 0] | data_in | 写入数据 |
| input | [MAX_ROW_BITS - 1 : 0] | row_out | 输出数据的行坐标 |
| input | [MAX_COLUMN_BITS - 1 : 0] | column_out | 输出数据的纵坐标 |
| output | [15 : 0] | data_out | 读出数据 |
坐标转化
row_in和column_in会转换为data_in_add传给memory,
data_in_add = {column_in[4 +: MAX_ROW_BITS - 4], row_in} //(column/16)*MAX_ROW+row
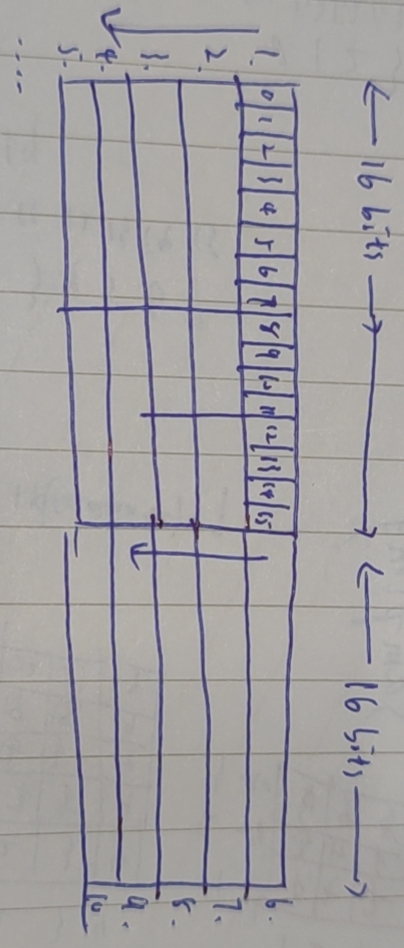
memory id的摆列如图所示,如row=0,column=1,data_in_add就是1
如row=17,column=1,data_in_add就是7
读写权限sweep
考虑到每次计算完一帧matrix后需要把整个matrix从temp覆写到real matrix上,对memory来说过于复杂,
因此计划实例化两个memory_cell分别交替进行读写操作
此步骤由变量switch负责,
| switch | mem_1 | mem_2 |
|---|---|---|
| 1 | write | read |
| 0 | read | write |
switch会在检测到finish信号上升沿后变化
结果
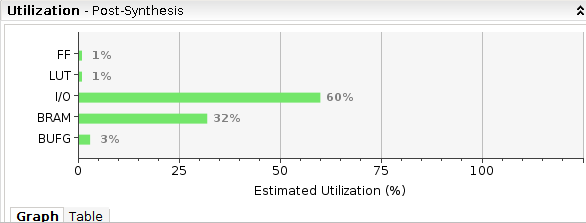
在512X512数据下已经占用32%BRAM,考虑到需要给VGA显存保留空间,在不改变逻辑前提下最大的matrix size可能只能达到512*1024
2023/05/26
- 编写了VGA显存逻辑和支持
- 配套鼠标和7-segments显示
- 上板子测试通过
VGA显存逻辑
VGA显存设计为1024X512大小RAM存储,每次只能保存或读取一bit数据
直接通过VGA address存读数据
VGA reader逻辑
根据05.19内的VGA显示逻辑,控制FPGA在当前时序内读取显存内存储的数据,并输出对应颜色。
注意必须在25MHz下设置VGA逻辑,否则会无法显示
已通过在现存内设置初始值来测试单个点显示功能
配套鼠标和7-segments
利用之前microprocessor内轮子,直接嵌套模块
将鼠标原本8bits数据输出转换为12bits输出,方便显示480X640像素坐标
将原本7-segments的左右各输出x,y坐标,改为只显示x或y坐标,并通过外部控制切换,方便完全显示数据
暂时设置为鼠标按下时显示鼠标路径,测试模拟VGA数据改变。测试成功
结果
图片忘拍了,之后补上
2023/05/29
几天的内容一起补上,实现了VGA显示cell图像,加鼠标控制的逻辑
- 实现了VGA显示保存的matrix图像
- 可以用上下键控制单个cell大小
- 可以用鼠标中键移动画布
- 可以用鼠标左键点亮新的cell
- 可以用鼠标右键按灭cell
VGA写入
因为在每次开始VGA显示前总有一段时间是没用显示的,可以乘此机会写入buffer下一帧VGA的数据
但这个间隔时间又不够完全写入(大概只能写入一半的数据),但因为VGA的读取速度远小于写入速度(VGA clk为25Mhz,写入频率为100Mhz)
所以可以在上一帧完成显示后开始写入下一帧,直到写入完成
在此过程中会出现buffer前面在读取,后面在写入的情况,不过不需要担心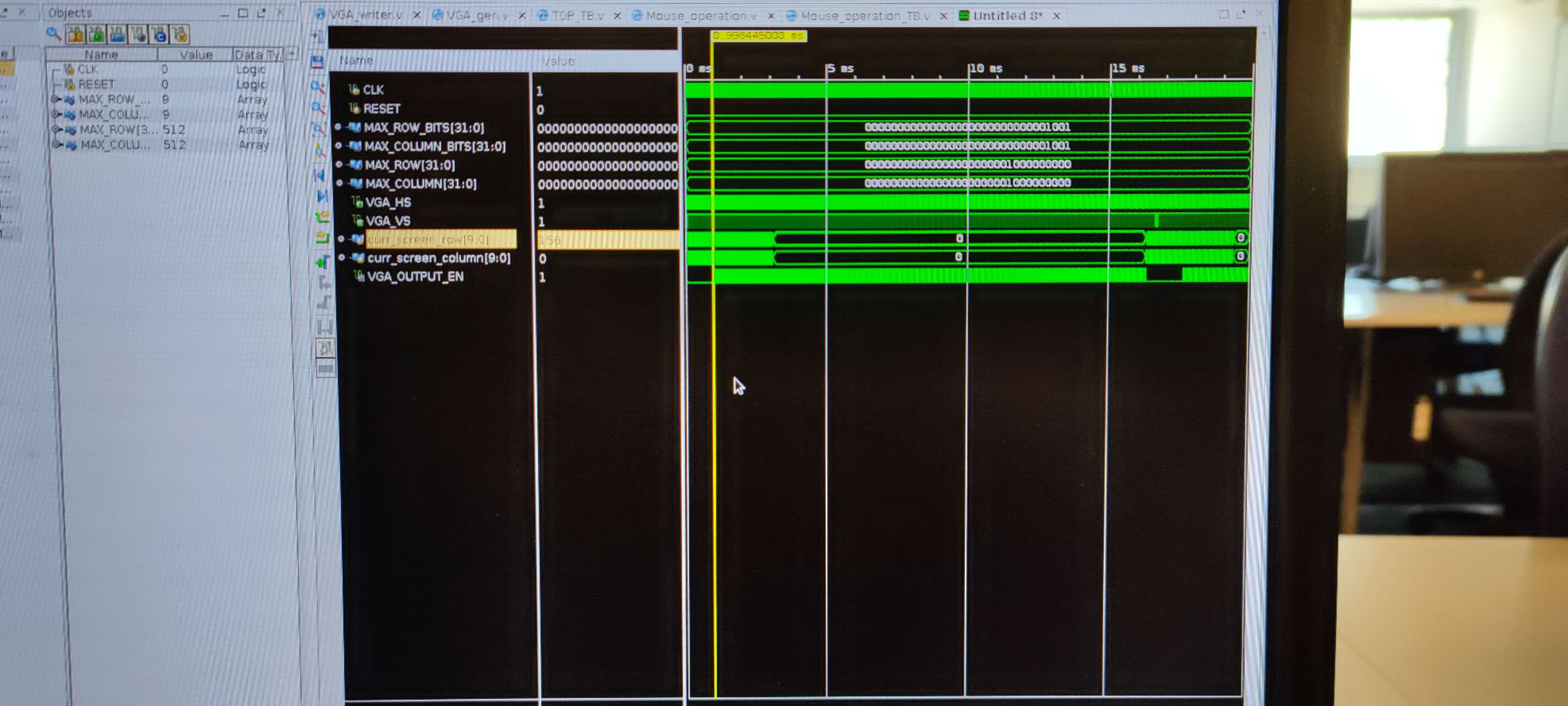
倒数第二行是写入数据,最后一行是读取数据
VGA像素生成
这一块用了pipline方法,每一个clk查询写入一个像素
因为查询cell的状态需要一个cycle,所以记得注意相关时序问题
而从VGA像素转换到cell坐标需要以下数据:
- 单个cell长度 cell_length
- 最左上角那个点相比(0,0)的偏移像素值 start_row/column_pixcle
- 当前扫到的VGA绝对位置 curr_screen_row/column
当前VGA像素所代表的cell坐标可以计算为:
cell_coordinate = (curr_screen_row/column + start_row/column_pixcle) / cell_length
注:当前鼠标所在像素所代表的cell坐标也可以这么转换
调整单个cell大小
FPGA板子上的上下键可以将cell_length左移/右移一位,来更改cell大小
cell最大为64像素,最小为1像素
平移画布
当按下鼠标中键时可以拖动画布
这是通过改变start_row/column_pixcle的值实现的
当鼠标中键按下时,可以以像素级的精度平移画布
增加/消除cell
按下鼠标左键/右键可以分辨添加/消除cell的颜色
注意,需要将enter开关关掉才能输入(只有在停止matrix迭代时才能手动变化cell)
总结
至此VGA方面的逻辑已基本完成,VGA和cell memory之间的连接也已实现
BRAM的利用率已经尽可能调到最大,现在最大可支持1024X512的matrix
之后只要把主逻辑的功能进行完善进行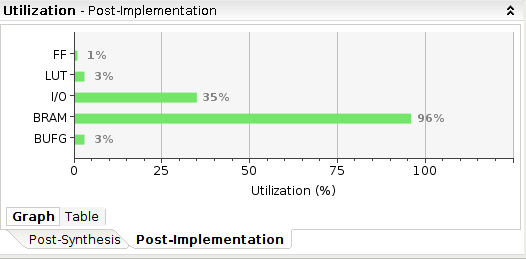
2023/06/08
这几天完成了所有游戏主逻辑的重构和验证,已可以正常运行游戏
- 设计了两种不同的数据读取方式,淘汰了其中一种
- 成功连接了memory和游戏逻辑之间的wire
- 将上下按键设计为调整画布大小的功能,并在7-segments上显示当前画布大小
游戏主逻辑大概思路
主逻辑主要由三块构成,读取数据,计算数据,输出数据
在读取数据方面,程序将读取一整列数据,之后再读取下一列。
由于采用了pipeline,在大数据量的情况下计算效率接近16 bits/ CLK
计算出来后就将数据传输给memory储存
主逻辑将在等待VGA_writer结束运行后开始,以避免数据memory读取冲突
结束后会输出finish信号,来切换两个memory读写状态,并等待下一次运行
基于memory结构,main_data是以16bits一组的形式读出来的,程序会等前三行数据都读到后才开始第一次计算
数据计算
每个clk都会输入3组18bits的数据row_1, row_2, row_3,
每组数据都是{1 bit left_neighbor, 16 bits main_data, 1 bit right_neighbor}的结构
将会在下一个CLK输出16 bits next_main_data
例如:
row_1: 0 0000000000000000 0
row_2: 0 1111111111111111 1
row_3: 0 0000000000000001 1
下一个clk:
OUT: 0111111111111110
读取数据
读取的最大问题是读取main_data时很难一起吧left_neighbor,right_neighbor一起读出来
废弃逻辑
最开始是计划在memory读取main_data时顺便一起输出左右数据,这样读取数据就可以直接将{1 bit left_neighbor, 16 bits main_data, 1 bit right_neighbor}的结构数据传递给计算模块。
这在逻辑层面非常好实现,但问题在巨大的memory_LUT资源占用
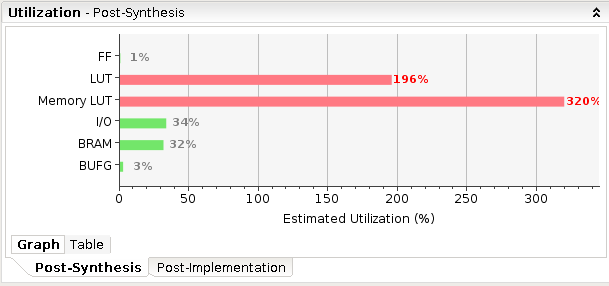
随废弃
成功逻辑
后来计划使用一种比较复杂的逻辑:
Cache会先储存第一组16列数据,结构为{1bit left_neighbor, 16bits main_data}
其中第一行和最后一行会保存为0,表示为边界
之后,temp_cahce会逐行读取下一组16列内的数据,并向上sweep
例如,第一个CLK三个temp_cache数据为:
0: 0000 0000 0000 0000
1: 0000 0000 0000 0001
2: 1111 1111 1111 1111
下一个CLK就为:
0: 0000 0000 0000 0001
1: 1111 1111 1111 1111
2: 1111 0000 1111 0000
其中2中新的数据就是从memory中新读取的数据
而原本0中的老数据会替换cache内相应位置的数据,以准备下一次循环的运算
简而言之,Cache会暂时保存先前一组16列数据,因为当时程序只知道这16列数据的左边邻居是谁(就是保存在Cache最左边的那个bit),但还没读到右边邻居,所以先将他们保存起来。而当程序读到右边那组16列数据时,他就知道了上一组数据的左边邻居,即temp_cache最左边的那个数。所以可以将数据发送给计算单元,同时把temp_cache(0)那个数保存到Cache内,把之前在cache的那个数的最右边bit当作新加入数的左边邻居,准备进行下一个循环。
例如,现在我已经直到了Cache前三个数为:
1: 0 0000 0000 0000 0000
2: 0 0000 0000 0000 1111
3: 0 1111 1111 0000 0000
temp_cahce的值为:
1: 0000 0000 0000 0000
2: 1111 1111 0000 1111
3: 0000 1111 1111 0000
那么就可以将一组数据发给计算模块:{17bits Cache, 1bits temp_cache[n][0]}
row_1: 0 0000000000000000 0
row_2: 0 0000000000001111 1
row_3: 0 1111111100000000 0
然后下一个CLK计算模块会输出15bits结果,并交给memory储存
数据连接
主要的需要处理数据连接是memory处的数据筛选,
因为memory输入读取地址位是由VGA和游戏逻辑模块共享的,
因此会有两个signal来控制谁来占用这个共用地址位
在VGA_writer工作时,读取地址位只由VGA占用
在游戏逻辑模块工作时,读取输入地址只被逻辑模块占用
其实由于这两个模块是互相运行的,不会实际冲突,这个措施只是相当于再次确认
结果
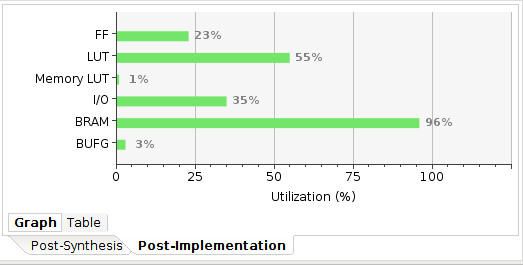
注意:由于Cache一口气储存了最大512X16bits数据,会有巨量LUT占用。这提升了运算效率,但现在看来是超前优化,用处不大
程序可以正常运行,速度在最大画布(1024X512)下仍可以60Hz运行。如果不需要VGA显示的话甚至可以每秒处理 16X100MHz=1600M个像素点,即在60Hz下最大可运行5163X5163画布大小的矩阵
同时UI和控制画布大小的方式仍可以改进的人性化一点,但苦于学校项目,只能是后会有期了。